This is the last part of a 3-parts series. In part 1, I tried to make sense of how it works and what we are trying to achieve, and in part 2, we set up the training loop.
Model Predictions
We have a trained model. Now what?
Remember, a model is a series of giant matrices that take an input like you trained it on, and spits out the list of probabilities associated with the outputs you trained it on. So all you have to do is feed it a new input and see what it tells you:
let input = [1.0, 179.0, 115.0]
let unlabeled : Tensor<Float> = Tensor<Float>(shape: [1, 3], scalars: input)
let predictions = model(unlabeled)
let logits = predictions[0]
let classIdx = logits.argmax().scalar! // we take only the best guess
print(classIdx)
17
Cool.
Cool, cool.
What?
Models deal with numbers. I am the one who assigned numbers to words to train the model on, so I need a translation layer. That's why I kept my contents structure around: I need it for its vocabulary map.
The real code:
let w1 = "on"
let w2 = "flocks"
let w3 = "settlement"
var indices = [w1, w2, w3].map {
Float(contents.indexHelper[$0.hash] ?? 0)
}
var wordsToPredict = 50
var sentence = "\(w1) \(w2) \(w3)"
while wordsToPredict >= 0 {
let unlabeled : Tensor<Float> = Tensor<Float>(shape: [1, 3], scalars: indices)
let predictions = model(unlabeled)
for i in 0..<predictions.shape[0] {
let logits = predictions[i]
let classIdx = logits.argmax().scalar!
let word = contents.vocabulary[Int(classIdx)]
sentence += " \(word)"
indices.append(Float(classIdx))
indices.remove(at: 0)
wordsToPredict -= 1
}
}
print(sentence)
on flocks settlement or their enter the earth; their only hope in their arrows, which for want of it, with a thorn. and distinction of their nature, that in the same yoke are also chosen their chiefs or rulers, such as administer justice in their villages and by superstitious awe in times of old.
Notice how I remove the first input and add the one the model predicted at the end to keep the loop running.
Seeing that, it kind of makes you think about the suggestions game when you send text messages eh? 😁
Model Serialization
Training a model takes a long time. You don't want a multi-hour launch time on your program every time you want a prediction, and maybe you even want to keep updating the model every now and then. So we need a way to store it and load it.
Thankfully, tensors are just matrices, so it's easy to store an array of arrays of floats, we've been doing that forever. They are even Codable out of the box.
In my particular case, the model itself needs to remember a few things to be recreated:
the number of inputs and hidden nodes, in order to recreate the Reshape and LSTMCell layers
the internal probability matrices of both RNNs
the weigths and biases correction matrices
Because they are codable, any regular swift encoder will work, but I know some of you will want to see the actual matrices, so I use JSON. It is not the most time or space efficient, it does not come with a way to validate it, and JSON is an all-around awful storage format, but it makes a few things easy.
My resulting JSON file is around 70MB (25 when bzipped), so not too bad.
When you serialize your model, remember to serialize the vocabulary mappings as well! Otherwise, you will lose the word <-> int translation layer.
That's all , folks!
This was a quick and dirty intro to TensorFlow for some, Swift for others, and SwiftTensorflow for most.
It definitely is a highly specialized and quite brittle piece of software, but it's a good conversation piece next time you hear that ML is going to take over the world.
Feel free to drop me comments or questions or corrections on Twitter!
This is the second part of a series. If you haven't, you should read part 1...
Model Preparation
The text I trained the model on is available on the Gutenberg Project. Why this one? Why not?
It has a fairly varied vocabulary and a consistency of grammar and phrase structures that should trigger the model. One of the main problems of picking the wrong corpus is that it leads to cycles in the prediction with the most common words, e.g. "and the most and the most and the most and the" because it's the pattern that you see most in the text. Tacitus, at least, should not have such repetitive turns of phrase. And it's interesting in and of itself, even though it's a bit racist, or more accurately, elitist. 😂
One of the difficult decisions is choosing the type of network we will be trying to train. I tend to have fairly decent results with RNNs on that category of problems so that's what I'll use. The types and sizes of these matrices is wayyyyy beyond the scope of this piece, but RNNs tend to be decent generalists. Two RNN/LSTM layers of 512 hidden nodes will give me enough flexibility for the task and good accuracy.
What are those and how do they work? You can do a deep dive on LSTM and RNN on Wikipedia, but the short version is, they work well with sequences because the order of the input is in and of itself one of the features it deals with. Recommended for handwriting recognition, speech recognition, or pattern analysis.
Why two layers? The way you "nudge" parameters in the training phase means that you should have as many layers as you think there are orders of things in your dataset. In the case of text pattern recognition, you can say that what matters is the first order of recognition (say, purely statistical "if this word then this word") or you can add a second order where you try to identify words that tend to have similar roles in the structure (e.g. subject verb object) and take that into account as well. Higher orders than that, in this particular instance, have very little meaning unless you are dealing with, say, a multilingual analysis.
That's totally malarkey when you look at the actual equations, but it helps to see it that way. Remember that you deal with probabilities, and that the reasoning the machine will learn is completely alien to us. By incorporating orders in the model, you make a suggestion to the algorithm, but you can't guarantee that it will take that route. It makes me feel better, so I use it.
Speaking of layers, it is another one of these metaphors that help us get a handle of things, by organizing our code and the way the algorithm treats the data.
You have an input, it will go through a first layer of probabilities, then a second layer will take the output of the first one, and apply its probabilities, and then you have an output.
Let's look at the actual contents of these things:
Input is a list of trigrams associated with a word ( (borrowing a warrant) -> from, (his father Laertes) -> added, etc
The first layer has a single input (the trigram), and a function with 512 tweakable parameters to output the label
The second layer is trickier: it takes the 512 parameters of the first layer, and has 512 tweakable parameters of its own, to deal with the "higher order" of the data
It sounds weird, but it works, trust me for now, you'll experiment later.
The very first step is "reshaping" the trigrams so that LSTM can deal with it. We basically turn the matrices around and chunk them so that they are fed to the model as single inputs, 3 of them, in this order. It is actually a layer of its own called Reshape.
And finally, we need to write that using this model requires these steps:
reshape
rnn1
rnn2
get something usable out of it
The code, then the comments:
struct TextModel : Layer {
@noDerivative var inputs : Int
@noDerivative var hidden : Int
var reshape : Reshape<Float>
var rnn1 : RNN<LSTMCell<Float>>
var rnn2 : RNN<LSTMCell<Float>>
var weightsOut : Tensor<Float> {
didSet { correction = weightsOut+biasesOut }
}
var biasesOut : Tensor<Float> {
didSet { correction = weightsOut+biasesOut }
}
fileprivate var correction: Tensor<Float>
init(input: Int, hidden: Int, output: Int, weights: Tensor<Float>, biases: Tensor<Float>) {
inputs = input
self.hidden = hidden
reshape = Reshape<Float>([-1, input])
let lstm1 = LSTMCell<Float>(inputSize: 1, hiddenSize: hidden)
let lstm2 = LSTMCell<Float>(inputSize: hidden, hiddenSize: hidden)
rnn1 = RNN(lstm1)
rnn2 = RNN(lstm2)
weightsOut = weights
biasesOut = biases
correction = weights+biases
}
@differentiable
func runThrough(_ input: Tensor<Float>) -> Tensor<Float> {
let reshaped = reshape.callAsFunction(input).split(count: inputs, alongAxis: 1)
let step1 = rnn1.callAsFunction(reshaped).differentiableMap({ $0.cell })
let step2 = rnn2.callAsFunction(step1).differentiableMap({ $0.cell })
let last = withoutDerivative(at:step2[0])
let red = step2.differentiableReduce(last, { (p,e) -> Tensor<Float> in return e })
return red
}
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
let step2out = runThrough(input)
let step3 = matmul(step2out, correction)
return step3
}
}
The RNN/LTSM have been talked about, but what are these two functions?
callAsFunction is the only one needed. I have just decided to split the algorithm in two: the part where I "just" pass through layers, and the part where I format the output. Everything in runThrough could be written at the top of callAsFunction.
We follow the steps outlined previously, it all seems logical, even if the details aren't quite clear yet.
What is it with the @noDerivative and @differentiable annotations?
Because we are dealing with a structure (model, layer, etc...) that not only should but will be adjusted over time, it is a way to tell the system which parts are important to that adjustment:
all properties except those maked as not derivative will be nudged potentially, so it makes sense to mark the number of inputs as immutable, and the rest as "nudgeable"
all the functions that calculate something that will be used in the "nudging" need to have specific maths properties that make the change non-random. We need to know where we are and where we were going. We need a position, and a speed, we need a value and its derivative
Ugh, maths.
Yeah.
I am obviously oversimplifying everything to avoid scaring away everyone from the get go, but the idea should make sense if you look at it this way:
Let's take a blind man trying to shoot an arrow at a target
You ask them to shoot and then you'll correct them based on where the arrow lands
It hits the far left of the target
You tell them to nudge the aim to the right
The problem is that "more right" isn't enough information... You need to tell them to the right a little (new position and some information useful for later, you'll see)
The arrow lands slightly to the right of the center
You tell the archer to aim to the left but less than their movement they just made to the right.
Two pieces of information: one relative to a direction, and one relative to the rate of change. The other name of the rate of change is the derivative.
Standard derivatives are speed to position (we are here, now we are there, and finally we are there, and the rate of change slowed, so the next position won't be as far from this one as the one was to the previous one), or acceleration to speed (when moving, if your speed goes up and up and up, you have a positive rate of change, you accelerate).
That's why passing through a layer should preserve the two: the actual values, and the speed at which we are changing them. Hence the @differentiable annotation.
(NB for all you specialists in the field reading that piece... yes I know. I'm trying to make things more palatable)
"But wait", say the most eagle-eyed among you, "I can see a withoutDerivative in that code!"
Yes. RNN is peculiar in the way that it doesn't try to coerce the dimensions of the results. It spits out all the possible variants it has calculated. But in practice, we need only the last one. Taking one possible outcome out of many cancels out the @differentiable nature of the function, because we actually lose some information.
This is why we only partially count on the RNN's hidden parameters to give us a "good enough" result, and need to incorporate extra weights and biases that are derivable.
The two parts of the correction matrix, will retain the nudge speed, as well as reshape the output matrix to match the labels: matrix addition and multiplications are a bit beyond the scope here as well (and quite frankly a bit boring), but that last step ( step3 in the code ) basically transform a 512x512x<number of labels> matrix, into a 2x<numbers of labels> : one column to give us the final probabilities, one for each possible label.
If you've made it this far, congratulations, you've been through the hardest.
Model Training
OK, we have the model we want to use to represent the various orders in the data, how do we train it?
To continue with the blind archer metaphor, we need the piece of code that acts as the "corrector". In ML, it's called the optimizer. We need to give it what the archer is trying to do, and a way to measure how far off the mark the archer is, and a sense of how stern it should be (do we do a lot of small corrections, or fewer large ones?)
The measure of the distance is called the "cost" function, or the "accuracy" function. Depending on how we look at it we want to make the cost (or error) as low as possible, and the accuracy as high as possible. They are obviously linked, but can be expressed in different units ("you are 3 centimeters off" and "you are closer by 1%"). Generally, loss has little to no meaning outside of the context of the layers ( is 6 far? close? because words aren't sorted in any meaningful way, we are 6.2 words away from the ideal word doesn't mean much), while accuracy is more like a satisfaction percentage (we are 93% satisfied with the result, whatever that means).
let predictions = model(aBunchOfFeatures)
let loss = softmaxCrossEntropy(logits: predictions, labels: aBunchOfLabels)
print("Loss test: \(loss)")
Loss test: 6.8377414
In more human terms, the best prediction we have is 10% satisfying, because the result is 6.8 words away from the right one. 😬
Now that we know how to measure how far off the mark we are (in two different ways), we need to make a decision about 3 things:
Which kind of optimizer we want to use (we'll use Adam, it's a good algorithm for our problem, but other ones exist. For our archer metaphor, it's a gentle but firm voice on the corrections, rather than a barking one that might progress rapidly at first then annoy the hell out of the archer)
What learning rate we want to use (do we correct a lot of times in tiny increments, or in bigger increments that take overall less time, but might overcorrect)
How many tries we give the system to get as close as possible
You can obviously see why the two last parameters are hugely important, and very hard to figure out. For some problems, it might be better to use big steps in case we find ourselves stuck, for others it might be better to always get closer to the target but by smaller and smaller increments. It's an art, honestly.
Here, I've used a learning rate of 0.001 (tiny) and a number of tries of 500 (medium), because if there is no way to figure out the structure of the text, I want to know it fast (fewer steps), but I do NOT want to overshoot(small learning rate).
Let's setup the model, the correction matrices, and the training loop:
var weigths = Tensor<Float>(randomNormal: [512, contents.vocabulary.count]) // random probabilities
var biases = Tensor<Float>(randomNormal: [contents.vocabulary.count]) // random bias
var model = TextModel(input:3, hidden: 512, output: contents.vocabulary.count, weights: weigths, biases: biases)
Now let's setup the training loop and run it:
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
var randomSampleSize = contents.original.count/15
var randomSampleCount = contents.original.count / randomSampleSize
print("Doing \(randomSampleCount) samples per epoch")
for epoch in 1...epochCount {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for training in contents.randomSample(splits: randomSampleCount) {
let (sampleFeatures,sampleLabels) = training
let (loss, grad) = model.valueWithGradient { (model: TextModel) -> Tensor<Float> in
let logits = model(sampleFeatures)
return softmaxCrossEntropy(logits: logits, labels: sampleLabels)
}
optimizer.update(&model, along: grad)
let logits = model(sampleFeatures)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: sampleLabels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epoch % 10 == 0 {
print("avg time per epoch: \(t.averageDeltaHumanReadable)")
print("Epoch \(epoch): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
A little bit of explanation:
We will try 500 times ( epochCount )
At each epoch, I want to test and nudge for 15 different combinations of trigrams. Why? because it avoids the trap of optimizing for some specific turns of phrase
We apply the model to the sample, calculate the loss, and the derivative, and update the model with where we calculate we should go next
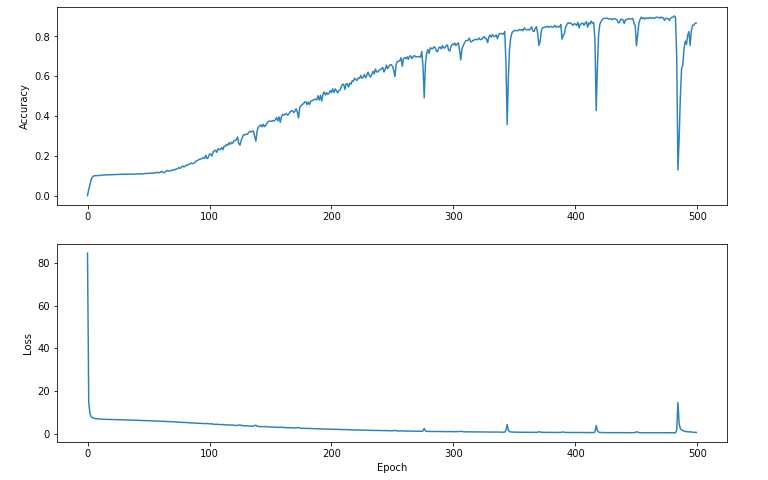
We like to keep these values in an array to graph them. What does it look like?
We can see that despite the dips and spikes, because we change the samples often and don't try any radical movement, we tend to better and better results. We don't get stuck in a ditch.
Next part, we'll see how to use the model. Here's a little spoiler: I asked it to generate some random text:
on flocks settlement or their enter the earth; their only hope in their arrows, which for want of it, with a thorn. and distinction of their nature, that in the same yoke are also chosen their chiefs or rulers, such as administer justice in their villages and by superstitious awe in times of old.
It's definitely gibberish when you look closely, but from a distance it looks kind of okayish for a program that learned to speak entirely from scratch, based on a 10k words essay written by fricking Tacitus.
First part of doing RNN text prediction with TensorfFlow, in Swift
Broad Strokes
For all intents and purposes, it's about statistics. The question we are trying to solve is either something along the lines of "given an input X, what is the most probable Y?", or along the lines of "given an input X, what is the probability of having Y?"
Of course, simple probability problems have somewhat simple solutions: if you take a game of chess and ask for a next move based on the current board, you can do all the possible moves and sort them based on the probability of having a piece taken off the board, for instance. If you are designing an autopilot of some kind, you have an "ideal" attitude (collection of yaw, pitch and roll angles), and you calculate the movements of the stick and pedals that will most likely get you closer to that objective. If your last shot went left of the target, chances are, you should go right. Etc etc etc.
But the most interesting problems don't have obvious causality. If you have pasta, tomatoes and ground meat in your shopping basket, maybe your next item will be onions, because you're making some kind of bolognese, maybe it will be soap, because that's what you need, maybe it will be milk, because that's the order of the shelves you are passing by.
Machine learning is about taking a whole bunch of hopefully consistent data (even if you don't know for sure that it's consistent), and use it to say "based on this past data, the probabilities for onions, soap and milk are X, Y, and Z, and therefore the most probable is onions.
The data your are basing your predictive model on is really really important. Maybe your next item is consistent with the layout of the shop. Maybe it is consistent with what other customers got. Maybe it's consistent to your particular habits. Maybe it's consistent with people who are in the same "category" as you (your friends, your socio-economic peers, your cultural peers, ... pick one or more).
So you want a lot of data to have a good prediction, but not all the data, because noise (random data) does not reveal a bias (people in the shop tend to visit the shelves in that order) or doesn't exploit a bias (people following receipes want those ingredients together).
Oh yes, there are biases. Lots of them. Because ML uses past data to predict the future, if the data we use was based on bad practices, recommendations won't be a lot better.
There is a branch of machine learning that starts ex nihilo but it is beyond the scope of this introduction, and generates data based on a tournament rather than on actual facts. Its principle is roughly the same, though.
So, to recap:
We start with a model with random probabilities, and a series of "truths" ( X leads to Y )
We try with a Z, see what the model predicts
We compare it to a truth, and fix the probabilities a little bit so that it matches
Repeat with as many Zs as possible to be fairly confident the prediction isn't too far off
If you didn't before, now you know why ML takes a lot of resources. Depending on the number of possible Xs, Ys and the number of truths, the probability matrix is potentially humongous. Operations (like fixing the probabilities to match reality) on such enormous structures aren't cheap.
There are a few contenders in the field of "ML SDK", but one of the most known is TensorFlow, backed by Google. It also happens to have a Swift variant (almost every other ML environment out there is either Python or R).
And of course, the documentation is really... lacking, making this article more useful than average along the way.
In their "Why Swift?" motivation piece, the architects make a good case, if a little bit technical, as to why swift makes a good candidate for ML.
The two major takeaways you have to know going in are:
It's a different build of Swift. You cannot use the one that shipped with Xcode (yet)
It uses a lot of Python interoperability to work, so some ways of doing things will be a bit alien
The performance is rather good, comparable or better than the regular Python TensorFlow for the tasks I threw at it, so there's that.
Sometimes, that page greets me in Greek... But hey, why not. There is little to no way to navigate the hierarchy, other than going on the left side, opening the section (good luck if you don't already know if it's a class, a protocol or a struct you're looking for), and if you use the search field, it will return pages about... the Python equivalents of the functions you're looking for.
Clearly, this is early in the game, and you are assumed to know how regular TensorFlow works before attempting to do anything with STF.
But fret not! I will hold your hand so that you don't need to look at the doc too much.
The tutorials are well written, but don't go very far at all. Oh and if you use that triple Dense layers on more than a toy problem (flower classification that is based on numbers), your RAM will fill so fast that your computer will have to be rebooted. More on that later.
And, because the center of ML is that "nudge" towards a better probability matrix (also called a Tensor), there is the whole @differentiable thing. We will talk about it later.
A good thing is that Python examples (there are thousands of ML tutorials in Python) work almost out of the box, thanks to the interop.
Data Preparation
Which Learning will my Machine do?
I have always thought that text generation was such a funny toy example (if a little bit scary when you think about some of the applications): teach the machine to speak like Shakespeare, and watch it spit some play at you. It's also easy for us to evaluate in terms of what it does and how successful it is. And the model makes sense, which helps when writing a piece on how ML works.
A usual way of doing that is using trigrams. We all know than predicting the next word after a single word is super hard. And our brains tend to be able to predict the last word of a sentence with ease. So, a common way of teaching the machine is to have it look at 3 words to predict a 4th.
I am hungry -> because, the birds flew -> away, etc
Of course, for more accurate results, you can extend the number of words in the input, but it means you must have a lot more varied sentence examples.
What we need to do here is assign numbers to these words (because everything is numbers in computers) so that we have a problem like "guess the function f if f(231,444,12)->123, f(111,2,671)->222", which neural networks are pretty good at.
So we need data (a corpus), and we need to split it into (trigram)->result
Now, because we are ultimately dealing with probabilities and rounding, we need the input to be in Float, so that the operations can wriggle the matrices by fractions, and we need the result to be an Int, because we don't want something like "the result is the word between 'hungry' and 'dumb'".
The features (also called input) and the labels (also called outputs) have to be stored in two tensors (also called matrices), matching the data we want to train our model on.
That's where RAM and processing time enter the arena: the size of the matrix is going to be huge:
Let's say the book I chose to teach it English has 11148 words in it (it's Tacitus' Germany), that's 11148*3-2 trigrams (33442 lines in my matrices, 4 columns total)
The way neural networks function, you basically have a function parameter per neuron that gets nudged at each iteration. In this example, I use two 512 parameters for somewhat decent results. That means 2 additional matrices of size 33442*512.
And operations regularly duplicate these matrices, if only for a short period of time, so yea, that's a lot of RAM and processing power.
Here is the function that downloads a piece of text, and separates it into words:
func loadData(_ url: URL) -> [String] {
let sem = DispatchSemaphore(value: 0)
var result = [String]()
let session = URLSession(configuration: URLSessionConfiguration.default)
// let set = CharacterSet.punctuationCharacters.union(CharacterSet.whitespacesAndNewlines)
let set = CharacterSet.whitespacesAndNewlines
session.dataTask(with: url, completionHandler: { data, response, error in
if let data = data, let text = String(data: data, encoding: .utf8) {
let comps = text.components(separatedBy: set).compactMap { (w) -> String? in
// separate punctuation from the rest
if w.count == 0 { return nil }
else { return w }
}
result += comps
}
sem.signal()
}).resume()
sem.wait()
return result
}
Please note two things: I make it synchronous (I want to wait for the result), and I chose to include word and word, separately. You can keep only the words by switching the commented lines, but I find that the output is more interesting with punctuation than without.
Now, we need to setup the word->int and int->word transformations. Because we don't want to look at all the array of words every time we want to search for one, there is a dictionary based on the hashing of the words that will deal with the first, and because the most common words have better chances to pop up, the array for the vocabulary is sorted. It's not optimal, probably, but it helps makes things clear, and is fast enough.
func loadVocabulary(_ text: [String]) -> [String] {
var counts = [String:Int]()
for w in text {
let c = counts[w] ?? 0
counts[w] = c + 1
}
let count = counts.sorted(by: { (arg1, arg2) -> Bool in
let (_, value1) = arg1
let (_, value2) = arg2
return value1 > value2
})
return count.map { (arg0) -> String in
let (key, _) = arg0
return key
}
}
func makeHelper(_ vocabulary: [String]) -> [Int:Int] {
var result : [Int:Int] = [:]
vocabulary.enumerated().forEach { (arg0) in
let (offset, element) = arg0
result[element.hash] = offset
}
return result
}
Why not hashValue instead of hash? turns out, on Linux, which this baby is going to run on, the values are more stable with the latter rather than the former, according to my tests.
The data we will work on therefore is:
struct TextBatch {
let original: [String]
let vocabulary: [String]
let indexHelper: [Int:Int]
let features : Tensor<Float> // 3 words
let labels : Tensor<Int32> // followed by 1 word
}
We need a way to initialize that struct, and a couple of helper functions to extract some random samples to train our model on, and we're good to go:
extension TextBatch {
public init(from: [String]) {
let v = loadVocabulary(from)
let h = makeHelper(v)
var f : [[Float]] = []
var l : [Int32] = []
for i in 0..<(from.count-3) {
if let w1 = h[from[i].hash],
let w2 = h[from[i+1].hash],
let w3 = h[from[i+2].hash],
let w4 = h[from[i+3].hash] {
f.append([Float(w1), Float(w2), Float(w3)])
l.append(Int32(w4))
}
}
let featuresT = Tensor<Float>(shape: [f.count, 3], scalars: f.flatMap { $0 })
let labelsT = Tensor<Int32>(l)
self.init(
original: from,
vocabulary: v,
indexHelper: h,
features: featuresT,
labels: labelsT
)
}
func randomSample(of size: Int) -> (features: Tensor<Float>, labels: Tensor<Int32>) {
var f : [[Float]] = []
var l : [Int32] = []
for i in 0..<(original.count-3) {
if let w1 = indexHelper[original[i].hash],
let w2 = indexHelper[original[i+1].hash],
let w3 = indexHelper[original[i+2].hash],
let w4 = indexHelper[original[i+3].hash] {
f.append([Float(w1), Float(w2), Float(w3)])
l.append(Int32(w4))
}
}
var rf : [[Float]] = []
var rl : [Int32] = []
if size >= l.count || size <= 0 {
let featuresT = Tensor<Float>(shape: [f.count, 3], scalars: f.flatMap { $0 })
let labelsT = Tensor<Int32>(l)
return (featuresT, labelsT)
}
var alreadyPicked = Set<Int>()
while alreadyPicked.count < size {
let idx = Int.random(in: 0..<l.count)
if !alreadyPicked.contains(idx) {
rf.append(f[idx])
rl.append(l[idx])
alreadyPicked.update(with: idx)
}
}
let featuresT = Tensor<Float>(shape: [f.count, 3], scalars: f.flatMap { $0 })
let labelsT = Tensor<Int32>(l)
return (featuresT, labelsT)
}
func randomSample(splits: Int) -> [(features: Tensor<Float>, labels: Tensor<Int32>)] {
var res = [(features: Tensor<Float>, labels: Tensor<Int32>)]()
var alreadyPicked = Set<Int>()
let size = Int(floor(Double(original.count)/Double(splits)))
var f : [[Float]] = []
var l : [Int32] = []
for i in 0..<(original.count-3) {
if let w1 = indexHelper[original[i].hash],
let w2 = indexHelper[original[i+1].hash],
let w3 = indexHelper[original[i+2].hash],
let w4 = indexHelper[original[i+3].hash] {
f.append([Float(w1), Float(w2), Float(w3)])
l.append(Int32(w4))
}
}
for part in 1...splits {
var rf : [[Float]] = []
var rl : [Int32] = []
if size >= l.count || size <= 0 {
let featuresT = Tensor<Float>(shape: [f.count, 3], scalars: f.flatMap { $0 })
let labelsT = Tensor<Int32>(l)
return [(featuresT, labelsT)]
}
while alreadyPicked.count < size {
let idx = Int.random(in: 0..<l.count)
if !alreadyPicked.contains(idx) {
rf.append(f[idx])
rl.append(l[idx])
alreadyPicked.update(with: idx)
}
}
let featuresT = Tensor<Float>(shape: [f.count, 3], scalars: f.flatMap { $0 })
let labelsT = Tensor<Int32>(l)
res.append((featuresT,labelsT))
}
return res
}
}
In the next part, we will see how to set the model up, and train it.
Super fascinating attempt at creating a model that looks for errors and/or style issues in code using neural networks in this article from Sam Gentle.
Machine learning is the kind of thing where you can get a tantalising result in a week, and then spend years of work turning it into something reliable enough to be useful. To that end, I hereby provide a tantalising result and leave the years of work as an exercise for the reader.
It's very hard to escape a few buzzwords in our field, and at the moment ML is one of those words, in conjunction with things that smell kind of where ML would like to go (looking at you "AI").
This week's WWDC was choke full of ML tools and sessions, and their Apple's Core ML technology is really impressive. But ML isn't for everything and everyone (looking at you, "blockchain"), and I hope that by explaining the principles under the hood, my fellow developers will get a better understanding of how it works to decide by themselves when and how to use it.
• I see maths everywhere!
Let's get back to school maths for a sec. I will probably mistype a coupla formulas, but here goes.
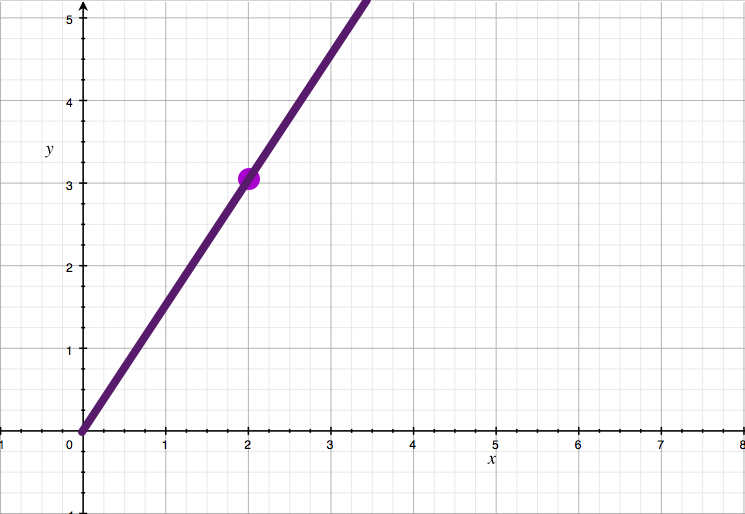
Let's say I have a point in a plane and I want to figure out what the line going through that point P and the origin is.
Easy problem right? It's just y = (P.y/P.x) * x
Similarly, most of us still know that the line going through 2 points P and Q on a plane has the equation: y = (Q.y-P.y)/(Q.x-P.x) * x + c where c is a monstrosity that's easy to calculate but has a terrible form (it's (Q.x-P.x)*P.y + (P.y-Q.y)*P.x).
We tend to remember the slope part but not the constant part because 1/ it's usually more useful to know, and 2/ once you figure this out, you have y = a*x + c, and you just have to plug the coordinates of one of the two points to calculate it, so it's "easy". Just sayin.
Anyways, if I give you two points and I tell you that this is how things go, you can use that line to extrapolate new information.
Let's say I tell you that the grade of your exam is function of your height. If you know that this 1.70m person had 17 and that this 1.90m person had 19, you can very easily figure out what your own grade will be. This is called a predictive model. I'll introduce a couple more terms while I'm at it: whatever feeds into the model is a feature (your height), and whatever comes out is a label (your grade).
Let's get back to the dots and lines.
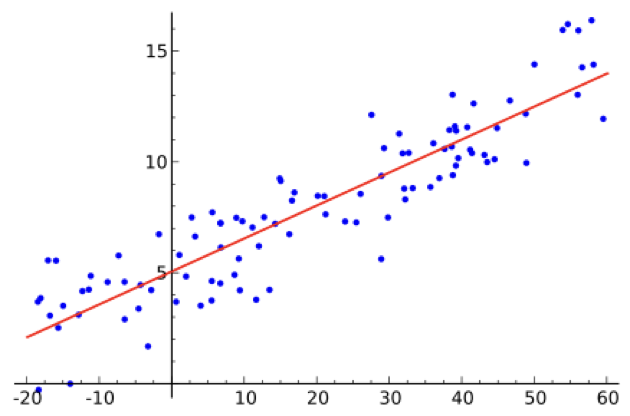
What's the equation of a line that goes through 3 points? 99.999999999% of the time, it will be a triangle, not a line. If you have hundreds or thousands of points, the concept of a line going through all of them becomes completely absurd.
So, ok, let's change tacks. What is the line that fits most of the data? In other words, what's the line that is as close as possible to all of the points?
OK, this is the part where it gets a bit horrendous for us developers, and I will expand on it afterwards.
You can compute the shortest distance between a point and a line using the following:
line: A*x + B*y + C = 0
point: (m,n)
distance: | A*m + B*n + C | / √(A²+B²)
(code-ish): abs(A*m + B*n + C) / sqrt(A*A+B*B)
Yes, our friend Pythagoras is still in the building. I'll leave the explanation of that formula as homework.
So you can say that the total error is the sum of all the distances between your prediction (the line) and the data (the points), or the average distance. Because it's computationnally super expensive, in ML we tend to use the distance on only one of the axises... axisis... axs... the coordinates in the system x, or y, depending on the slope. Then we square it, to emphasize the points that are super far from the line while more or less ignoring the ones close to the line.
Once we have the error between the prediction and the actual data, we tweak a bit A, B and C and we compute the error again. If it makes the error go down, we twiddle in the same direction again, if not, we twiddle in the other direction. When the error doesn't change much anymore, we have found a local minimum to the error, and we have a line that's not bad, all things considered. Remember this, it will be important later.
There's a lot of maths about local minima vs global minima, how to twiddle the parameters right, how to do the same thing in more dimensions (your height and your age and the length of your hair factor in your grade), and not trying to fit a line, but a parabola (x²) or a more generic polynomial function, etc etc etc, but to discuss the principle of the thing and its limitations, simple linear regression (the thing we just saw) is enough to get the point across. If you use more complicated maths, you'll end up having a more complicated line equation, and a more complicated error calculus, but the steps will remain the same.
Based on that very very short summary of what we are trying to do, two problems should jump out of the page:
what if the data doesn't want to be lying anywhere near a curve?
wow, ok, that's a lot of calculations at each step
• Data scientisting is hard, mkay?
If the data doesn't fit neatly on a vaguely recognizable shape, there are two options: there is no correlation or you got the data wrong.
Think back to the grading system from earlier. Of course this isn't a good grading system. And if by some freak accident my students find a correlation between their height and their grade, I will be crucified.
The actual job of a data scientist isn't to look at a computer running ML software that will spit out magic coefficients for lines. It's to trawl for days or weeks in data sets that might eventually fit on a somewhat useful predictive model. The canonical example is the price of a house. Yes it's dependant on the size of the house, but also the neighborhood, and the number of bathrooms, and the sunlight it gets etc... It never fits perfectly with x money per 1 m². But if you tweak the parameters a bit, say by dividing the size by the number of rooms, you might end up with something close enough.
As developers, this is something we tend to shun. Things have value x, not weeeeeell it's kind of roughly x, innit?. But real life isn't as neat as the world inside a computer, so, deal with it.
That's why data scientists get mucho dineros, because their job is to find hidden patterns in random noise. Got to be a bit insane to do that, to begin with. I mean, isn't it the most prevalent example of going crazy in movies? Sorry, I digress.
That's why sane (and good) data scientists get много рублей.
• A brute force approach that is now possible
It seems that most of what "Machine Learning" is about is fairly simple maths and the brain power of prophets. Well it is and there's nothing new to these methods. We've been using them in meteorology, economics, epidemiology, genetics, etc, since forever. The main problem lied in the fact that all those calculations took ages. In and of themselves they aren't hard. A reasonably diligent hooman can do it by hand. If we had an infinite amount of monkeys... no, wrong analogy.
So... what changed?
In a word: parallelization. Our infrastructures now can accomodate massively parallel computation, and even our GPUs can hold their own on doing simple maths like that at an incredible speed. GPUs were built to calculate intersections and distances between lines and points. That's what 3D is.
Today, on the integrated GPU of my phone, I can compute the average error of a model on millions of points in a few seconds, something that data scientists even 20 years ago would do by asking very nicely to the IT department for a week of mainframe time.
• What about ML for vision? or for stuff that isn't about numbers?
Everything is numbers. It just depends on what you look at and how.
An image is made of pixels, which are in turn made of color components. So there's some numbers for ya. But for image recognition, it's not really that useful. There are a number of ways we can identify features in an image (a dark straight line of length 28 pixels could be one, or 6 circles in this image), and we just assign numbers to them. They become our features. Then we just let the machine learn that if the input is that and that and that feature, we tend to be looking at a hooman, by twiddling the function a lil bit this way or that way.
Of course, the resulting function isn't something we can look at, because it's not as pretty or legible as y = a*x + b, but it's the exact same principle. We start with a function that transforms the image into a number of mostly relevant features, that feeds that combination of values to a function that spits out it's a hooman or it's not a hooman.
If the result isn't the right one, maybe we remove that feature and start again... the fact that there are 6 circles in that image isn't correlated to the fact that it's a hooman at all. And we reiterate again, and again, and again, and again, until the error between the prediction and the reality is "sufficiently" small.
That's it. That's what ML is about. That's all Machine Learning does today. It tries a model, finds out how far from the truth it is, tweaks the parameters a bit, then tries again. If the error goes down, great, we keep going in that direction. If not, then we go the other way. Rince, repeat.
• OK, so?
You can see why developers a bit preoccupied about performance and optimizations have a beef with this approach. If you do the undirected learning (I won't tell you if it's a line, or a parabola, or anything else, just try whatever, like in vision), it's a horrendous cost in terms of computing power. It also explains why, in all the WWDC sessions, they show models being trained offline, and not learning from the users' actions. The cost of recomputing the model every time you add a handful of data points would be crazy.
It also helps to look at the data with your own eyes before you go all gung-ho about ML in your applications. It could very well be that there is no possible way to have a model that can predict anything, because your data doesn't point at any underlying structure. On the other hand, if what you do is like their examples, about well-known data, and above all mostly solved by a previous model, you should be fine to just tweak the output a bit. There's a model that can identify words in a sentence? We can train a new model that builds upon that one to identify special words, at a very low cost.
Just don't hope to have a 2s model computation for a 1000 points dataset on an iPhone SE, that's all.
• ML ≠ AI
Something to remember is that marketing people love talking about "AI" in their ML technobabble. What you can clearly see in every session led by an engineer is that they avoid that confusion as best as they can. We don't know what intelligence is, let alone artificial intelligence. ML does produce some outstanding results, but it does so through a very very stupid process. But the way Machine Learning works today can't tackle every problem under the sun. It can only look at data that can be quantified (or numberified for my neology-addicted readers), and even then, that data has to have some sort of underlying structure. A face has a structure, otherwise we wouldn't be able to recognize it. Sentences have structures, most of the time, that's how we can communicate. A game has structure, because it has rules. But a lot of data out there doesn't have any kind of structure that we know of. I won't get all maudlin on you and talk about love and emotions, because, well, I'm a developer, but I'm sure you can find a lot of examples in your life that seem to defy the very notion of causality (if roughly this, then probably that), and that's the kind of problem ML will fail at. It may find a model that kinda works some of the time, but you'd be crazy to believe its predictions.
If you want to dig deeper, one of the best minds who helped give birth to the whole ML thing has recently come out to say that Machine Learning isn't a panacea.
As developers, we should never forget that we need to use the right tools for the job. Hammers are not a good idea when we need to use screws.