
It's very hard to escape a few buzzwords in our field, and at the moment ML is one of those words, in conjunction with things that smell kind of where ML would like to go (looking at you "AI").
This week's WWDC was choke full of ML tools and sessions, and their Apple's Core ML technology is really impressive. But ML isn't for everything and everyone (looking at you, "blockchain"), and I hope that by explaining the principles under the hood, my fellow developers will get a better understanding of how it works to decide by themselves when and how to use it.
• I see maths everywhere!
Let's get back to school maths for a sec. I will probably mistype a coupla formulas, but here goes.
Let's say I have a point in a plane and I want to figure out what the line going through that point P and the origin is.
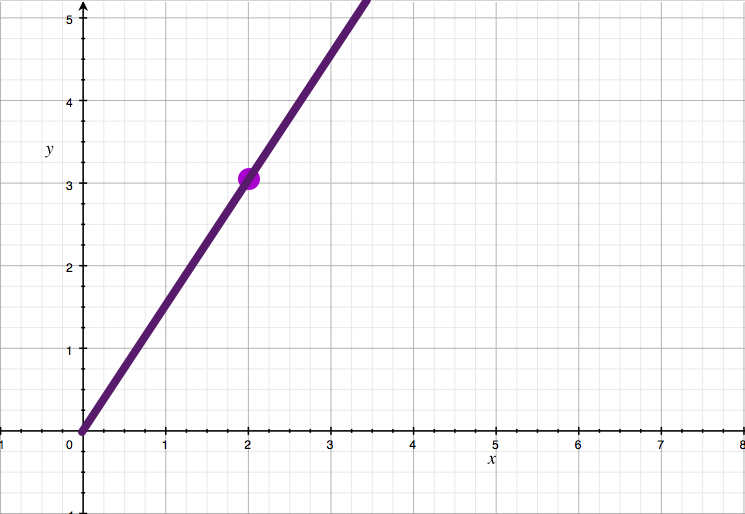
Easy problem right? It's just y = (P.y/P.x) * x
Similarly, most of us still know that the line going through 2 points P and Q on a plane has the equation: y = (Q.y-P.y)/(Q.x-P.x) * x + c where c is a monstrosity that's easy to calculate but has a terrible form (it's (Q.x-P.x)*P.y + (P.y-Q.y)*P.x).
We tend to remember the slope part but not the constant part because 1/ it's usually more useful to know, and 2/ once you figure this out, you have y = a*x + c, and you just have to plug the coordinates of one of the two points to calculate it, so it's "easy". Just sayin.
Anyways, if I give you two points and I tell you that this is how things go, you can use that line to extrapolate new information.
Let's say I tell you that the grade of your exam is function of your height. If you know that this 1.70m person had 17 and that this 1.90m person had 19, you can very easily figure out what your own grade will be. This is called a predictive model. I'll introduce a couple more terms while I'm at it: whatever feeds into the model is a feature (your height), and whatever comes out is a label (your grade).
Let's get back to the dots and lines.
What's the equation of a line that goes through 3 points? 99.999999999% of the time, it will be a triangle, not a line. If you have hundreds or thousands of points, the concept of a line going through all of them becomes completely absurd.
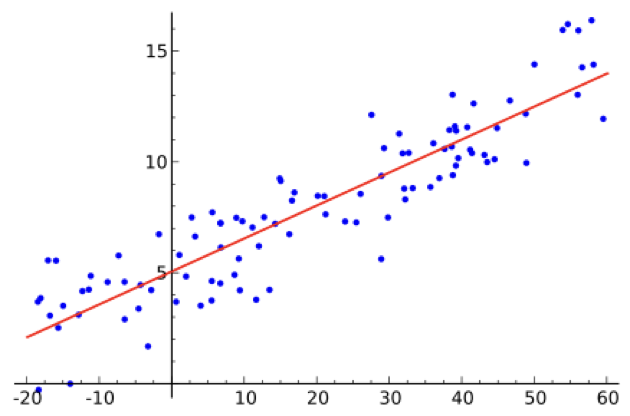
So, ok, let's change tacks. What is the line that fits most of the data? In other words, what's the line that is as close as possible to all of the points?
OK, this is the part where it gets a bit horrendous for us developers, and I will expand on it afterwards.
You can compute the shortest distance between a point and a line using the following:
line: A*x + B*y + C = 0
point: (m,n)
distance: | A*m + B*n + C | / √(A²+B²)
(code-ish): abs(A*m + B*n + C) / sqrt(A*A+B*B)
Yes, our friend Pythagoras is still in the building. I'll leave the explanation of that formula as homework.
So you can say that the total error is the sum of all the distances between your prediction (the line) and the data (the points), or the average distance. Because it's computationnally super expensive, in ML we tend to use the distance on only one of the axises... axisis... axs... the coordinates in the system x, or y, depending on the slope. Then we square it, to emphasize the points that are super far from the line while more or less ignoring the ones close to the line.
Once we have the error between the prediction and the actual data, we tweak a bit A, B and C and we compute the error again. If it makes the error go down, we twiddle in the same direction again, if not, we twiddle in the other direction. When the error doesn't change much anymore, we have found a local minimum to the error, and we have a line that's not bad, all things considered. Remember this, it will be important later.
There's a lot of maths about local minima vs global minima, how to twiddle the parameters right, how to do the same thing in more dimensions (your height and your age and the length of your hair factor in your grade), and not trying to fit a line, but a parabola (x²) or a more generic polynomial function, etc etc etc, but to discuss the principle of the thing and its limitations, simple linear regression (the thing we just saw) is enough to get the point across. If you use more complicated maths, you'll end up having a more complicated line equation, and a more complicated error calculus, but the steps will remain the same.
Based on that very very short summary of what we are trying to do, two problems should jump out of the page:
- what if the data doesn't want to be lying anywhere near a curve?
- wow, ok, that's a lot of calculations at each step
• Data scientisting is hard, mkay?
If the data doesn't fit neatly on a vaguely recognizable shape, there are two options: there is no correlation or you got the data wrong.
Think back to the grading system from earlier. Of course this isn't a good grading system. And if by some freak accident my students find a correlation between their height and their grade, I will be crucified.
The actual job of a data scientist isn't to look at a computer running ML software that will spit out magic coefficients for lines. It's to trawl for days or weeks in data sets that might eventually fit on a somewhat useful predictive model. The canonical example is the price of a house. Yes it's dependant on the size of the house, but also the neighborhood, and the number of bathrooms, and the sunlight it gets etc... It never fits perfectly with x money per 1 m². But if you tweak the parameters a bit, say by dividing the size by the number of rooms, you might end up with something close enough.
As developers, this is something we tend to shun. Things have value x, not weeeeeell it's kind of roughly x, innit?. But real life isn't as neat as the world inside a computer, so, deal with it.
That's why data scientists get mucho dineros, because their job is to find hidden patterns in random noise. Got to be a bit insane to do that, to begin with. I mean, isn't it the most prevalent example of going crazy in movies? Sorry, I digress.
That's why sane (and good) data scientists get много рублей.
• A brute force approach that is now possible
It seems that most of what "Machine Learning" is about is fairly simple maths and the brain power of prophets. Well it is and there's nothing new to these methods. We've been using them in meteorology, economics, epidemiology, genetics, etc, since forever. The main problem lied in the fact that all those calculations took ages. In and of themselves they aren't hard. A reasonably diligent hooman can do it by hand. If we had an infinite amount of monkeys... no, wrong analogy.
So... what changed?
In a word: parallelization. Our infrastructures now can accomodate massively parallel computation, and even our GPUs can hold their own on doing simple maths like that at an incredible speed. GPUs were built to calculate intersections and distances between lines and points. That's what 3D is.
Today, on the integrated GPU of my phone, I can compute the average error of a model on millions of points in a few seconds, something that data scientists even 20 years ago would do by asking very nicely to the IT department for a week of mainframe time.
• What about ML for vision? or for stuff that isn't about numbers?
Everything is numbers. It just depends on what you look at and how.
An image is made of pixels, which are in turn made of color components. So there's some numbers for ya. But for image recognition, it's not really that useful. There are a number of ways we can identify features in an image
(a dark straight line of length 28 pixels could be one, or 6 circles in this image), and we just assign numbers to them. They become our features. Then we just let the machine learn that if the input is that and that and that feature, we tend to be looking at a hooman, by twiddling the function a lil bit this way or that way.
Of course, the resulting function isn't something we can look at, because it's not as pretty or legible as y = a*x + b, but it's the exact same principle. We start with a function that transforms the image into a number of mostly relevant features, that feeds that combination of values to a function that spits out it's a hooman or it's not a hooman.
If the result isn't the right one, maybe we remove that feature and start again... the fact that there are 6 circles in that image isn't correlated to the fact that it's a hooman at all. And we reiterate again, and again, and again, and again, until the error between the prediction and the reality is "sufficiently" small.
That's it. That's what ML is about. That's all Machine Learning does today. It tries a model, finds out how far from the truth it is, tweaks the parameters a bit, then tries again. If the error goes down, great, we keep going in that direction. If not, then we go the other way. Rince, repeat.
• OK, so?
You can see why developers a bit preoccupied about performance and optimizations have a beef with this approach. If you do the undirected learning (I won't tell you if it's a line, or a parabola, or anything else, just try whatever, like in vision), it's a horrendous cost in terms of computing power. It also explains why, in all the WWDC sessions, they show models being trained offline, and not learning from the users' actions. The cost of recomputing the model every time you add a handful of data points would be crazy.
It also helps to look at the data with your own eyes before you go all gung-ho about ML in your applications. It could very well be that there is no possible way to have a model that can predict anything, because your data doesn't point at any underlying structure. On the other hand, if what you do is like their examples, about well-known data, and above all mostly solved by a previous model, you should be fine to just tweak the output a bit. There's a model that can identify words in a sentence? We can train a new model that builds upon that one to identify special words, at a very low cost.
Just don't hope to have a 2s model computation for a 1000 points dataset on an iPhone SE, that's all.
• ML ≠ AI
Something to remember is that marketing people love talking about "AI" in their ML technobabble. What you can clearly see in every session led by an engineer is that they avoid that confusion as best as they can. We don't know what intelligence is, let alone artificial intelligence. ML does produce some outstanding results, but it does so through a very very stupid process. But the way Machine Learning works today can't tackle every problem under the sun. It can only look at data that can be quantified (or numberified for my neology-addicted readers), and even then, that data has to have some sort of underlying structure. A face has a structure, otherwise we wouldn't be able to recognize it. Sentences have structures, most of the time, that's how we can communicate. A game has structure, because it has rules. But a lot of data out there doesn't have any kind of structure that we know of. I won't get all maudlin on you and talk about love and emotions, because, well, I'm a developer, but I'm sure you can find a lot of examples in your life that seem to defy the very notion of causality (if roughly this, then probably that), and that's the kind of problem ML will fail at. It may find a model that kinda works some of the time, but you'd be crazy to believe its predictions.
If you want to dig deeper, one of the best minds who helped give birth to the whole ML thing has recently come out to say that Machine Learning isn't a panacea.
As developers, we should never forget that we need to use the right tools for the job. Hammers are not a good idea when we need to use screws.