I love maths. I know it's not a popular topic in school, and comes with a lot of baggage for most people, but for me, looking at numbers and figuring out how they relate to each other or what they can tell me about the thing they measure is very engaging.
Unfortunately, maths is also something either very clunky or absent in most general purpose languages. As much as I appreciate Swift's largely successful attempt at preventing coding errors through various tricks like strong type and nil checking, concurrency enforcement, etc, using it for maths problems is somewhat difficult.
For reasons that are lost to the mists of time, I started working on a symbolic math representation in Swift.
What Is Symbolic Math And Why Do You Torture Yourself So?
When "doing maths", we tend to treat symbols (∂, ¬, x), but also numbers, as things that have no inherent value until you need it to. That's where you might have heard the expression "just plug in the numbers in the formula". "Alice's age is twice the age of Bob" has meaning, even when you don't know the precise ages of Alice and Bob. Of course, "twice" means "multiplied by two", but because we don't have the rest of the numbers yet, we treat 2 as another symbol, in this context. It will take the value 2 and allow me to calculate things if and when I get Alice's or Bob's age.
Symbolic math is basically your Xs and Ys, and working with them even though they don't have a definite value. They have a type though, and meaning, and other constraints that make working with those variables possible.
So far so good, it's exactly like the variables in your programs: they have a type, they can hold any value within that type, and you work with them until somewhere down the line something is done with them.
OK, so now, imagine you have an array of Int called versions.
What does versions - 1 mean?
What does versions > 1 mean?
In languages like Julia, you can broadcast a function to every single element in a collection, and because of various safeguards, it can even be done in parallel. In math-y languages some of the above statements actually have meaning, and automagically broadcast or filter the array.
This category of wants can be solved by defining operators and playing with the type system in Swift. We just have to agree on what it means:
extension Array where Element : SignedInteger {
static func + (left: Array<Element>, right: Element) -> Array<Element> {
if left.isEmpty { return [] }
return left.map { $0 + right }
}
static func - (left: Array<Element>, right: Element) -> Array<Element> {
if left.isEmpty { return [] }
return left.map { $0 - right }
}
}
let a = [0,1,2,3,4,5,6]
let b = a + 1
let c = a - 1
print(a)
print(b)
print(c)
But Swift is not built to manipulate unknowns. How do you define a variable that is definitely an Int but has no value yet? Most people will use Optionals to capture that: what is an Int? but an Int that doesn't have a value yet? The semantics of Int? + 2 by default are clear though: it is forbidden, you have to provide a default value in case of nil, and if you define the operator + to be able to handle the nil case, you kind of defeat the purpose of nil checking and the semantics of the operation are still murky.
Ultimately, that's because in maths we can do something like
- y = x + 2
- ...
- x = 1
and somehow, magically, y now evaluates to 3, whereas at the start, it didn't have any value, especially not nil.
The pointer-minded people among you might want to solve this kind of problem with classes or pointers and therefore have a y variable that can retroactively change values, and that works (kind of )! But it means going through hoops, and defining classes that have optionals in them, handle errors, etc...
What IS The Problem You Are Trying To Solve?
Because I was handling a lot of tabular data at the time, I wanted to be able to say "for every row, the column D contains the sum of the columns A and B, multiplied by C", without doing the actual calculation unless I needed it, and preferably defined once, for the whole column, instead of the copy-paste rigamarole of Excel-like software with their very dangerous reference system.
A
B
C
D
1
2
3
?
...
...
...
?
If I could somehow define D = (A + B) * C, instead of [D1 = (A1 + B1) * C1, D2 = (A2 + B2) * C2, ...], and have D contextually resolve to the right value when I need it, it would somehow feel... more elegant?
The syntactic idiosyncrasies of having the symbolic data as Strings is kind of iffy, but when you think about it, symbols are names, and I couldn't find another way to represent variables anyways. Plus they can be emojis or whatever. So I guess that's a bonus.
The eagle-eyed among you may have noticed I pass the values as inout. That's because the symbolic thing also handles systems:
let test = SYMSystem {
try (1 + 2 * "X") > (3 - "Y")
try "X" != "Y"
}
With the idea of passing them a Domain (from my repo HoledRange), and having the system give me back the applicable Domain for these variables.
One definite possible application is letting me know if there are no values that would satisfy this system, so that I don't bother calculating anything, and another one is identifying is there is like a single possible value for all the variables, which simplifies the calculus immensely as well.
Anyways, the project didn't go further than being satisfied by watching unit tests go green, and my probably unhealthy affection for maths, but the code is surprisingly small: without the Domain calculations, everything fits in 300 lines of code, most of which is extensions for normal types like Double and Int to conform to custom protocols, and operator overloads to handle this new kind of type.
But, even though I don't actually use it in production, how cool is that to be able to define a whole category of types and their syntactic sugar, just for the kick of seeing (1 + 2 * "X") * (3 - "Y") be a valid expression that has no current value, but can, at any moment, resolve to an actual usable number? And the equation system thing has potential, if I ever find the time and motivation to make it work fully, outside of toy cases.
OK, so, now that I don't spend my days teaching anymore, my friends and family are amazed at the fact that I can't stop learning new things, starting new projects, getting up at 6am and carrying on carrying on.
The worst part? I've kept the habit of a teacher and try to enthuse people about the stuff I discover / learn about... To mixed success.
This has led me to thinking about a worrying trend I find in online and offline conversations that may or may not be linked to conspiracy theories and "fringe" opinions.
The urge to publish was definitely tickled by this toot
Folks who don't understand AI like it more but once they understand it they find it less appealing
Where are you coming from?
First off, it's quite a big topic, one that can probably fill a few PhD thesises (thesii?) for a sociology/psychology department. This are just my thoughts about it, based on anecdotal evidence and cursory research. Feel free to hit me up about it, I'm totally open (and maybe even hoping) to be proven wrong.
As someone trained in linguistics, I feel the need to make sure the terms I'm using are somewhat well defined:
"Science" as in the process of learning or discovery (in a greek sense closer to Μάθημα - Máthēma, something like the act of learning) is kind of alive and kicking, albeit in a weird way
"Science" as in the established knowledge (in a greek sense closer to Γνόσι - Gnósī, whether collectively or privately) is very much in a state of active battle, and probably the one I have the most thoughts about
I'm sure some people will be thinking I'm preaching to the choir here, but I've seen with my own eyes the decline of visibility (in a positive sense) for the experts. Let me paint the scene for you:
We are in a meeting with half a dozen experts of their field and a couple of manager/investor types. The experts are disagreeing on many things but not on the most fundamental one: the proposal will not work. After the meeting, they are branded as killjoys, a vague social post arguing that the proposal is a good idea is brandished, and the decision to move forward is taken, to predictable results.
I'm not saying it's always the case, mind you. But more often than not, I have sat in auditoriums, meetings, what have you, and looked at a group of non-experts slowly but surely convincing themselves that the people they invited to talk (and sometimes even paid to do so) were wrong.
For someone who grew up in a time when science communicators were mostly researchers talking about their active research on live television, this is quite a culture shock. That's why I thoroughly enjoy youtube channels like Computerphile, who show actual research scientist being passionate, whether or not they are what is considered to be "good communicators" (and they are quite decent communicators, too!)
But the fact is, we have clearly entered an era where science communicators are permanent fixture. And I'm not throwing shade at them at all! They do a great and needed job.
But, when you ask them, one of the very first thing most of them will say is that they aren't "real" scientists (I beg to differ), and that they are like a gateway drug: get people interested in the topic so that they will dig deeper in the "actual" science.
What it feels like is that this worthy goal is never achieved.
The 10-minutes version of what could fill hours of lectures is enough: Γνόσι has been achieved, and Μάθημα is satisfied.
The problem is that it cuts both ways: a skilled communicator promoting pseudoscience will get the apparent same result as the one talking about what actual science says.
Milo Rossi (aka Miniminuteman on YouTube) has a fascinating lecture on his own field, right there on his channel
His central thesis seems to be that because communicating instantly to millions of people has become cheap, easy, and to some extent make enough money and/or fame back to the creator to encourage them to "challenge" the status quo, and find their audiences.
And, just like him, I find our position delicate: how do we promote the experts' words while not gatekeeping - preventing genuinely curious people to go and do their own research and experiments in good faith (as opposed to the derided "do your own research" mantra used by conspiracy theorists everywhere)?
Fine, but are you an expert in expertise?
Oof, good point, well made.
Here are my bona fides, and my experience on the matter. I will let you decide if it invalidates everything I have to say about it not.
I have been teaching classes in maths, computer science, data, and (machine) learning, as well as training other people in giving classes in front of audiences, for a couple of decades. There are definitely areas where I do decent, and others where I totally suck. You'll have to ask my students if I was overall a good teacher or not.
But objectively, a large majority of the people I trained went on to have a career in the field that I was in charge of teaching them, so I think it went decent. And while there were many, many, many, complaints, these are students we're talking about, and the power dynamic at play - me grading them based on "arbitrary" goals - means a somewhat antagonistic relationship, even when friendly. The grading game is a very heavy bias in your appreciation of teachers. I know. I even tested it: classes without an evaluation at the end tended to be lauded wayyyyyyyyy more than "strict" and friendly teachers.
Before we carry on with the central thesis of this post that will probably end up being way too long, here's a couple of observations I made as the head teacher / managing teacher of the curriculum:
I had the chance of heading a department where the jobs the students would get at the end paid very well. (Too well? Yes probably, especially given the fact we still refuse to be an industry)
Students attending class had a variety of incentives to specialize in CompSci, but let's not kid ourselves: making money was part of the equation.
The highest paying jobs are usually the ones requiring the most expertise, or at least this used to be the case.
So therefore, students should be trying to acquire as much expertise as possible, as fast as possible, to land those high-paying (and/or fun, and/or motivating, ...) jobs
Right?
Except: Students had a tendency to "check out" fairly rapidly
"Copypasta" has been a thing forever, but when your exam takes place on a machine literally designed to make the process of finding something on the web and copying it in your production easier (and now AI that automates - badly - most of it), the incentive to "waste" an hour on something that would "grade" the same in a minute is hard to find.
And during class, because the slides are available, or it's recorded, or there's a good chance to find a 10 minute video on "the same topic" online, why not do something more fun, and catch up later?
If the passing grade is 10/20, and having more isn't rewarded, why go the extra mile?
Subsequent conversations with them yielded interesting observations, on top of those fairly obvious ones. What they told me they yearned for was "engagement" or "entertainment". and it's a whole Thing. Make learning fun, they say!
While I do agree with the sentiment (learning is fun, to me), I find myself obligated to point out that in this particular instance, it doesn't have to be fun: they were ostensibly there to get a good paying job (among other things). I mean, I'm training people to compete with me for jobs and contracts, and I have to make them feel entertained?
Regardless of the validity of that demand, I always did strive to make the learning fun, because it's fun - to me. But I always found the reversal of expectations weird: here you are, asking me for a favor, and I have to thank you by entertaining you?
I totally understand how that may sound gatekeeper-y and demeaning. And, again, I never actually subscribed to that attitude, but when you think about it for a minute, there definitely is a difference between learning something that will be used to earn a living, and learning things without ulterior motives - at the beginning at least. Because of my well-ingrained biases regarding the former, I will keep the rest of this post to the latter: learning stuff that may not net an immediate advantage.
You're gonna talk about history now, aren't you?
Yes. Giving context and a bit of epistemology is part of the scientific method. Plus it's a fascinating topic in and of itself. It will happen.
I'm not going back too far though, only to the printing press, and the Renaissance (or Early Modern Era as I learned it should probably be called, because it was only a rebirth for Western Europe, not really the whole world where they didn't have our wonderfully repressive period known colloquially as the Dark Ages).
Scientists then, like now, had feuds about their hypothesises (hypothesi?), and wrote scathing articles, pamphlets, and letters, about their colleagues who were obviously wrong. Because of the wide dissemination of ideas and a general curiosity about how the world actually worked in a more practical way than "oh well, it's the will of a deity" or "well, my grandparents did it that way so it must carry on the same", there was a crowd - yes an actual crowd - coming to hear the latest discoveries at the various academies.
It's kind of like a Youtube channel, but you had to go to an auditorium once a month or whatever, to hear, usually from the mouth of the actual scientist or one of his proxies (student, secretary of the academy, colleague) what the exciting new scientific discovery was. And if you couldn't make it, there were local clubs and academies that would debate the written reports of the lecture.
Scientists were household names, and pride of their countries. You have a Gauss? Well we have a Newton! A lot of streets, buildings, and areas, are still named after them, and you were expected to be able to quote them before entering a debating arena.
And yet, there were close to no intermediary to the content of their theories: the people read the articles or letters verbatim. Science communication was without added value. If you wanted to participate in those discussions, you had to learn the whole thing, not just the cliff notes version.
The weird part is that while this feels super elitist - you have to be a world class mathematician to contribute to a discussion of the latest math discovery - it was fairly open. As long as you had enough free time (that is elitist, for different reasons) to learn, and could back your claims up in front of renowned scientists with the proper methodology, you were part of the club. A lot of scientists up until the Industrial Revolution were not just scientists. Enormous scientific discoveries and contributions were made by people with practical knowledge that wanted to find out the why, or people with a lot of free time just engaging in science out of curiosity.
That popular interest in discoveries and science continued unabated up until very recently. Scientific magazines, and, as I said before, scientists on TV, were very popular, up until the complete takeover of the Internet as a source of knowledge.
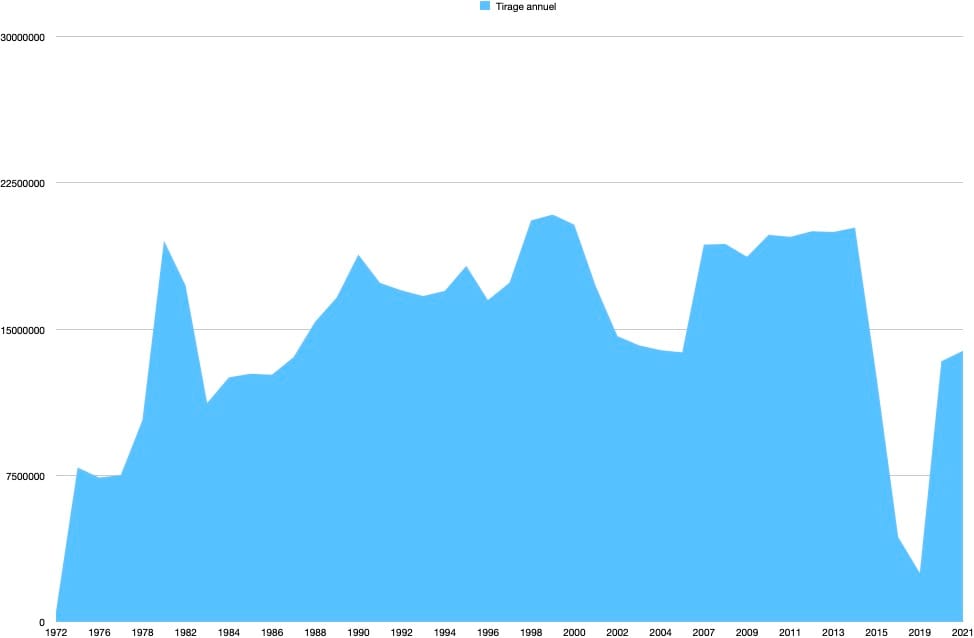
For reference, here are the circulation numbers for the scientific magazines here in France (may I suggest diving into those stats? Apart from being paper scans and sometimes hard to decipher, there aren't any regular format or nomenclature. Makes for a fun afternoon of research!):
"Science & Technique" category, in circulation numbers / year
What's surprising to me is the resurgence super recently. But you can clearly see the peak in 1981 among a global rise in interest about science & tech magazines, then the peak / dip around the Y2K bug, and since 2014-ish a sharp decline.
Obviously, this is only the number for France, and if you take a peek at the data itself, you'll see that there is a margin for error (what exactly is included in that category is arbitrary to a point). But it matches my gut feeling, so there is that.
Of course, nowadays, the undisputed royalty of scientific communication is the Internet. Science communicators have setup many very interesting channels, as I mentioned before, and most of the good ones are quite humble despite the fact that they have a viewership that the equivalent press would have considered a dream only a couple of decades ago.
Scientific honesty starts with, and carries on with, "I may be wrong" - always. Even when your theory (in the scientific sense, not in the vernacular "hypothesis" sense) seems to tick all the boxes and match all the data, there is a small chance that it could be at worse wrong except in this particular case, and at best right but only as as part of a more general theory. Again, watch people like Milo Rossi to see how they deconstruct their own certainties and doubts publicly.
So, with that historical context in place, let's talk about the iceberg.
The iceberg as in the thing that sunk the "insubmersible" Titanic?
More as in the thing that is mostly underwater. Because we have an Iceberg Problem.
The openness of science is still a thing most scientists strive for, but in order to understand - or even contribute - to modern research, you can't really do it in your free time and as a dilettante anymore, however brilliant.
Let me give you a personal example: I tried to teach a class on native mobile development. Despite what most platform vendors (and now IA vendors) would have you believe, software development isn't easy. Sure, if you have an image of something you want to put on the web (a landing page, a presentation page, anything that you could compose in a word processor or a page layout piece of software), making "a web site" that matches the visuals is fairly simple.
And, if you're only interested in what everybody else is doing, there's a good chance that someone out there does it already and could either sell it to you or give it for free.
This blog is easy to "make": I open a web browser, and type something in the window and blammo, you can read it. Except... this is only the tip of the iceberg.
Your web browser has more than 20 millions of lines of code, it runs on an operating system that is a couple of orders of magnitude more complex than that. And on my end, the server also has millions of lines of code. All of that requires maintenance by someone you don't know, and, more likely than not, that you haven't paid.
That's something of a marvel to me that despite the poor design choices we inherited, and the average number of bugs per 10k lines of code, when you write <center>something</center>, it is somewhat in the middle of the page. If it's not, then you're in for a whoooooooooooole lot of debugging time.
Back to my native development class: it's "lower level" than the web, which, in practice, means that there is one or two less layers of millions of lines of code for my "hello world" to be displayed somewhat properly. Oh and you add some real life issues such as battery and network performance into the mix, which you don't really have to care about "on the web".
What it meant is that my first class struggled with concepts and underpinnings that they never had to think about before. So I had to add more hours to the class. Then to add some pre-requisites in the years before. Then a whole new kind of course around designing and debugging code.
Because, you see, there's a whole lot of things under the hood that work just fine for 80% of what you want to do. The rest is trying to figure out why it doesn't and decide whether it requires a workaround of some weirdness in the underlying structure, or a completely new thing that has to be built from scratch.
In practice, what it means is that you can cobble something that looks like it's working fine enough without much training, but as your work is exposed to more users and situations, the probability of it breaking goes up exponentially. And you may not have any idea why.
Anyways, enough of my own field, it holds mostly true for every single one nowadays: in order to understand the current physics, the level of maths and prior work needed to "get it" is astounding. And it's an immediate turn off for a lot of folks.
Plus, because a lot of the most graspable concepts have been known and integrated into our lives for so long, the incentive to understand the current forefront of a scientific field boils sometimes down to "do I have time?" which correlates neatly to "what purpose does it serve?" and "how does it benefit me?"
If you knew the most current theories of physics, say 300 years ago, it might give you an edge in your daily life, like using levers instead of wrecking your back. Then it was about how does it help me "professionally"? Like using pulleys in your factory instead of 20 sweaty dudes. Nowadays? Practical applications of physics research may help someday a mega corporation that will sell me something that makes my life a lot easier.
So, it's all about curiosity, except when it's your job to be at the edge of what can be done.
But people still consume a lot of "educational" content, are they not?
Time for a tangent. Curiosity has always felt like a two-headed thing to me. There's "genuine" curiosity - as in "how is it possible? I'd like to know more about how or why this thing is" - which is almost always the starting point of research both personal and institutional, and there's ἐκρυπτός (ekrīptós), hermeticism, esotericism, arcanism, which are more about what I know that you don't, and is about power.
Because, yes, knowledge is power, even when it's not science. Power over people, power over situations, power over the machine,... If you know stuff, you're less passive, less at the mercy of whatever or whoever is guiding the situation you are in. And it's quite intoxicating to feel in control, or at least "understand the plan" for most people.
Just look at the success of gossip, magic tricks and the like! And in my field it's especially prevalent. If a company/freelancer doesn't tell the potential customer that it would probably cost a lot less to do their thing using a very well maintained and fairly easy to learn piece of free software, they may be able to extract quite a lot of monies from them.
That's why I'm particularly careful with science vulgarization in particular, and "knowledge" communication in general. Again, many people have written books and made videos and all that about it, but the incentives of the person giving you information factor in how I parse said information.
Now, the issue is, it's exactly what pseudoscience aficionados say as well. "The establishment (whatever that is) is lying to you, seek your own truth."
Let's talk incentives then shall we?
On the one hand, you have governmental and/or scientific cabals, that invest billions of monies into maintaining a fiction about some lie being the truth that involves thousands or millions of people that have to be bribed, coerced, intimidated, and what have you, in order to keep the "population" (ie you, and me) in a state of... compliance? Tranquility?
On the other hand, you have that person on the internet that knows the truth that is hidden and benefits financially and in terms of fame from your viewership.
Oh and those all powerful governments who managed to keep a lid on things for so long and at great expense somehow fail to take down the videos of Joe Schmock from Nowherville.
While doubting governments (because, yes, they do lie, hide and/or mismanage the truth sometimes) is totally fair in many many areas, science isn't "governmental". A random research team in Brazil do their thing, formulate hypotheseseseesses (hypothesi?), include them in a theory, and publish it for another set of random teams in Japan and Kenya to conform or deny.
You're telling me that the French government, which is publicly fighting with many governments over a lot of issues (and has warred because of it, too) is somehow coordinating with the UK to hide the truth about the moon landings while accusing them of lying about almost everything else?
Sorry about the choice of examples, but it's currently the 6 Nations tournament, and we French and English love to hate each other during tournaments. Especially Rugby. So, there. Apologies all around.
How does that relate to science being "too boring"?
Glad you asked. So, in my mind, the appetite for "trivia" or for useful knowledge (the kind that gives you a job, or power, or fame, or monies) hasn't abated at all. But actual modern science requires effort and dedication to understand.
Going back to my own field, if I can earn $10k with a customer who wants a website by doing $30 worth of work, why wouldn't I? (I mean except for honesty, ethics, love of humanity, long term reputation effects, risk of being found out as a fraud and a swindler, and many many more reasons)
And if I can tell that customer that they will never have the time to learn all the esoteric knowledge that justifies that price tag and they can't have a decent picture of the truth in my words, I win, right? (Power, again)
The reality is, most of my knowledge is boring tedium (for most people) about bits and bytes, algorithms that were thought of and perfected over a long period of time, a lot of "yea we do this like that because it's what we've always done, so all the tools are geared that way, like it or not", a dash of general understanding of maths and physics, and lots and lots and lots and lots of lessons learned from past mistakes.
In order to know as much as me, you don't have to be particularly smart. You have to put in the hours and do the mistakes. Experience is a catalog of dead ends that I know to avoid and you don't. It's as simple as that, mostly.
And most of science is that way: it's a pyramid that is now so high that no one has the time to learn from top to bottom, except for people whose job it is. But there is power to be gained from the tip. Funding for researchers, fame for communicants (and monies too), glory for nations, and, yes, all of the above for fakers and frauds too.
Once you start establishing your bona fides by explaining the layers your current expertise relies on, you are "boring" compared to your competition - the people who may not know as much as you, but are far more entertaining in their presentation - who just doesn't care about being right, just about being right enough.
And so we have pseudoscience that promises "secret knowledge" and power over your "sheeple" condition.
And we have noise about competing theories or discoveries for research grants.
And we have hiring issues.
In all my years training people, it's a sad observation to realize that it's not necessarily the most knowledgeable who get the high-paying job. I've met and trained genuinely curious, smart and motivated people who struggled to get hired. I've met single minded researchers that were working on something that could benefit humanity as a whole get their research grant denied, or so heavily hogtied with strings attached that it made the act of searching meaningless. It's not necessarily true for all the smart and/or knowledgeable people I've met, but the percentage is high enough to make me sad.
The scientific method works so well because it's predictable, open, and slow. As opposed to surprising, arcane, and fast. And therefore, yes, it's boring.
But it's boring in the same way that doing the scales and noodling on your instrument for hours before you take the stage is boring. It's boring in the same way the characters in your novel / movie / tv show slowly work towards winning at the end.
It's boring if you consider only the process and the ongoing effects, rather than the potential for apotheosis.
You said "AI" earlier. That was just clickbait, right?
Point of origin, rather than clickbait. And one I will address now.
These people have invested a lot of time, money and expertise, into trying to make products using AI, with customers who are very picky and take big risks when using their expertise in the field.
AI as it understood these days (LLMs, agents, domain-specific models,...) works of a pyramid of technologies and assumptions, some more hidden than others. What do I mean by that?
Without delving too deep in the technical side, the pipeline is as follows:
Gather a lot of data (assumption: this data is relevant to the rules, that data isn't)
From this data try to infer correlations and "rules" (assumption: there is a rule albeit an arcane one)
Compile these rules into a model (assumption: the modelling will capture the rules)
"Apply" the model to new data, and witness that if you follow those rules, the output should be X (assumption: new data will fit in the ruleset of the model)
For Large Language Models, the data is text. The system tries to infer words (or sequences of words) based on whatever words were given as input. If you build your model on questions and answers, what you get is something that will try to guess the probability on a sequence of words being the correct answer to another sequence of words that are considered to be a question.
That model will not be able to handle anything that is not a question, or that is a question but on a topic is has never seen before. Technically it's impossible.
And herein lies my problem with the current marketing of AI as a panacea: because most people do not understand the pipeline underneath, they cannot interpret the output properly: the model will always give you an answer, but with probabilities attached.
In my example, if I give my question/answer model the input "my dog barks at birds and the sky is blue", it might output something along the lines of "the sky is blue because of refraction in the atmosphere that scatters the red light" but with a probability (aka confidence) of 0.4.
If you've ever seen a matching algorithm (recommendation for buying stuff, dating sites, whatever), the underlying principle is the same... it tries to match an output with your input.
Now if you use the user-friendly version of whatever LLM you want, it won't give you that. It will output with absolute authority the answer that best matches your input, based on whatever data it was trained on. You usually do not get the nitty gritty probability numbers, and therefore how "confident" the model is it performed correctly.
On top of that, the companies that sell you access to their LLMs also have algorithms and rules that will parse the model's output and modify it, while hiding the inner workings, unless you write code to tap into the lower level - their APIs.
Their incentive is to look authoritative so that the product itself doesn't appear wonky (can you imagine a car salesman that would tell you the car may work fine a lot of times but they don't know if it will work on your driveway?) by hiding all the genuinely cool stuff underneath, and make it appear as magical and useful as possible.
BUT in order to have a somewhat reliable model, it has to be Large, because the moment the model encounters something completely outside of what it knows the probabilities of, it will output nonsense. And that precludes most of the personal experimentations that curious people may have.
The systems, principles and techniques are simple. Data in, a bit of probabilistic maths, and data (with attached probability) out. Having access to enough training data, and the computing power to find out the relationship between every possible input and every possible output is staggeringly difficult.
So you can't really check if the model was properly trained (or train it yourself), or even if the output has a high confidence, because the one thing that models can't do is say "I don't know". They will tell you instead gibberish, with a low confidence rating, which is their way of saying that they can't fulfill your desires. And that part is hidden for a large majority of the users.
And so we're back to asserting stuff with confidence, and the difficulty of distinguishing an actual expert from someone who can say stuff nice.
Not clickbait, alright?
I don't get it. Is science boring?
I don't think so. It requires a bit more effort nowadays than witnessing parlor tricks or being told in 10 minutes about a thing. But it also ranges quite far. We do things daily that were unthinkable a couple of generations ago.It's just that, because the effect is mundane, it's lost a bit of appeal. But it's still so fascinating and so cool, if you look at how such a mundane thing is done. Just last year in 2024, we accomplished things as a species that are completely and totally amazing, if you stop and think about it:
We're hopefully, finally, on the cusp of preventing HIV. A disease that infects more than a million people every year and kills two thirds of that. Every. Single. Year. And we are making progress in understanding the virus and fighting it. The cure isn't here yet, but we're getting better at preventing and fighting it.
Japan managed to soft land (ie not crash) a human sized object on the moon with a precision of a 100 meters, after a trip of 400 000 kms! That's like putting the billiard ball in the pocket from 440 km away. How's that not amazing?
Speaking of space, our species launched a spacecraft the size of car on a journey that will take 6 years, just to take a better look at a bunch of moons in orbit around Jupiter. We can do that.
We also found the oldest settlement to date in the Amazon rainforest, and we didn't even have to remove the trees to do so. Like, these cities were built and abandoned millenia ago, they are immensely difficult to access, and there was a decent chance it was just a fluke of nature to see patterns in the jungle, but with LIDAR and lots of careful analysis, those ruins are within the realm of human knowledge once again.
And I'm sure that in a field that you take an interest in, there were many advances and discoveries.
I may submit to the unknown, but never to the unknowable - Yama, Lord of Light, Roger Zelazny - 1967
I'm taking a break after a whole set of years managing the curriculum in a school, and I haven't sorted out my feelings just yet.
In the meantime, being unable to actually rest, I help friends, local associations, NGOs, and do some open-source. Everything that doesn't bring any shiny monies but makes me feel good.
So, I'll try and publish something (open-source, or blog, or video) on a regular basis to have some deadlines again.
I already started but I didn't feel like making a big deal out of it.
This project was in the works with my friend Peter Warner for a long long time. Ever since he passed, I had a hard time looking at it. Plus, it was in Objective-C and heavily dependent on CoreAnimation.
I am preparing a talk for Swift Connection in September, about data serialization.
So, I wanted to measure things.
Therefore I decided to use the (somewhat) new Benchmark package.
It has some weird idiosyncrasies (what package doesn't), but it's quite nice... until you try to run some CoreServices functions (CoreData, remember), because it can't run in macOS apps.
Why? After a couple of hours I came to the conclusion that it requires some entitlement / privileged mode.
So, no sweat, let's include it in a "real" Xcode project for an app.
Except, no, because Benchmark uses jemalloc, which is unsigned and plays havoc with the regular debugger's way of looking at memory.
That's fine! There's an environment variable that disables jemalloc. All I need to do is pass it to the SPM build system.
Except no. Xcode doesn't pass along those. Neither user defined settings, nor any other way that I could find.
Script build phase then! And link to the built product manually!
Nope, the linker freaks out.
OK, so maybe I can build an app directly from the package itself?
Turns out, I can. But I kinda sorta need SwiftUI, which isn't my forte. Fine.
I can fork the Benchmark repo, disable jemalloc, build an app and run the measurements from the UI, which enables all the standard system features.
All I need to do is debug SwiftUI weirdness vis-a-vis long-running heavy background tasks 😭
For reasons I took an interest in playing with Todo.txt. Naturally, I went and looked for a swift package capable of importing and exporting this format. It is surprisingly hard to find something that is somewhat recent and full-featured.
Anyways, I went with the intention of contributing to this package, both because I like its simplicity and the fact that it uses the new DSL semantics for the regexps. And boy, oh boy, it tested me.
The trouble with my brain
We are all products of our history. Regular expressions don't faze me one bit. I used to write parts of compilers, lexers and yaccers are old friends, and the whole lambda reduction way regexps work isn't new.
BUT I know that they are a major hindrance for a lot of newcomers. Their syntax is unlike anything they have ever encountered (well, except for when they use * to mean "zero or more characters"), and don't get me started on the whole capture groups ( especially in Javascript ).
So I came into this project thinking it would be half an hour of clever regexps, and that's it.
Oh noes, there's Builders
In theory, I love builders. SwiftUI may not be my favorite way to build UIs, but it's fun and it works. Ditto for Ktor's HTML/CSS DSLs.
For regular expressions though... to me they fail to capture (haha) the mechanics, and will work only for relatively simple expressions.
This is equivalent to \$([0-9]+\.[0-9][0-9])$ I guess, and it's actually an example of why the DSL system is easier: $ and . have meaning in regexps and have to be escaped. It makes that line totally undecipherable for most newcomers.
Let's set aside the fact that nesting too many builders leads to incredibly long type inference (when it doesn't fail) and compile time. It comes with the territory, SwiftUI afficionados will tell you.
Let's also set aside the compactness of the regexps versus the DSL type because it's irrelevant to the point. In any language, you can write your code as compact and illegible as you like, it doesn't mean it's better. The tradeoffs you choose for your project in terms of inclusiveness (towards more junior members, or at least with regard to the tech stack you are using), and maintainability (look at you being all clever and writing some l33tk0d3 that you won't be able to debug in 6 months time... I learned that lesson a while ago and have decided that in most cases, readability is better than cleverness).
The problem (for me) with DSLs as applied to regular expressions is that it fails to capture the mechanics of backtracking and cursor position.
How regular expressions kind of work
As anyone who's taken an algorithmics class will tell you, strings are a pain. They can mostly only been read linearly (going from one character to the next or the previous), they have encodings and special cases (pun intended), and what they contain mean something different to the programmer than the actual text it contains (looking at you JSON).
"17.51" kind of is a number, and most definitely a string. If an error creeps in, it becomes something really really tedious to deal with. Like "17.,51". What the hell does THAT mean? 17.0 followed by 51? Or is the comma used in the French way to separate the decimal part, and . for multiplication? 17 x 0.51 ? And don't get me started on dates...
And so we have to define rules and use pattern matching. You can say that the string contains elements separated by commas, and each element is a number. And if it isn't, raise an error.
Look for every combination of n digits, followed by an optional point, followed by m optional digits, followed by a comma OR the end of the line
You should end up with a list of n∂.m∂ strings, that you can now parse to floating point
That should give an expression that looks like this: ([0-9]+\.{0,1}[0-9]*)(,|$)
There's a lot of problems to unpack here, like the fact that we kind of have to capture the group matching the separator/end of line to keep the expression simple, the weird dance of square and curly brackets and parenthesiseseseses, the whys and the hows of + and *, and so much more. But this will suffice for a brief explanation of how it works under the hood.
See, the point of it all is state machines and backtracking. When you use the regexp on a string, it keeps track of what it's done, what it's trying to do and where to go next. And if the current attempt fails, it reverts back to a previous state. The experts in regexps will groan and moan because I explain things too casually, and they should, but you don't need the nitty gritty details of how it actually works to grasp what I'm getting at.
So let's look at "17.,.6,51", and try to apply the regular expression.
We are at character 0, and we are looking for 1 or more digits.
We find 17, so we look for 0 or 1 dot.
We find one, so we have 17., and we look for 0 or more digits
We find none, so we're still good, and we look for either a comma or the end of the line
We find a comma, so we have a complete match: 17.,
We push the result in the list of "found things", and advance the character to the end of the match, 3
We look again for a digit or more
We find none, so it can't be a match, so we advance by one character, and try again
Ditto for the dot
We're now at character 5, and try again
We have a digit, so we start a new match: 6
0 or more dots, check. 0 or more digits, check. Comma, check. So we have a new match: 6
Start again, and we find 51
In the end we have 3 matches: 17., 6, and 51 (plus the comma or end of line, that is captured in a separate group)
Hold on. It was .6 not 6! Well... yes, but not according to our rules. We have to have a digit before the dot.
Never you mind, you say, we'll say we can have 0 or more instead of one or more: ([0-9]*\.{0,1}[0-9]*)(,|$)
Yes, and it almost works the same:
Up to 51, we get almost identical results, except we do capture .6 instead of 6
BUT we're not done. We try the regexp again at the end of the string, because we have to look at it all, and we get:
There is 0 digit, followed by 0 dot, followed by 0 digit, followed by the end of the line. So there's an extra match: ""...
The two important parts to grasp from all this are that starting at the character we are at, we try to match the pattern to the rest of the string, and if it fails, we advance by one character, and try again. Current state, and backtracking to try again.
The weeds: lookaheads and negations
We need to talk about a couple of special cases:
What if we need to not match something (reject some characters, for example)?
What if we need to match things only if up ahead in the string there's something else (or not something else)?
Like, say, the dot should appear only if there are digits afterwards (we say that 17. isn't a valid number but 17.0, and .6, are). Or if we are dealing with dates (😖), the rules for matching depend on whether or not we have a time afterwards.
Using "normal" regexps, negation it is kind of easy: [^abc] will match anything but a, b or c. Note that the caret that is used to usually indicate "beginning of a line" is used for negation within the match... Yea. Oh and you have to list every character you do not wish to match.
So kind of a solution is to use "lookaheads". They are basically patterns that match (or not) things before or after the current character, but do not move the current character cursor. They kind of start their own internal state, disregarding the global state of the parent expression.
.*(?=,) means trying to find a comma, and matching anything ( .* ) up till then.
"17.,.6,51" and this pattern will match "17.,.6". Why is it stopping at the last comma instead of the first? Because .* is greedy, it tries to get as many characters as possible. Comma is a character, so it matches, until it can't anymore because it's the last comma.
We can amend the .* to a .*? which will act as a lazy matcher, stopping at the first occurence, and giving us 17., .6, and two empty strings. Because, yes, after we found 17. we try again starting there, and it does match "anything with a comma at the end".
We can also look backwards and see if anything before the current character matches something, with .*(?<=,), and both negations of these with... !. Because yea, caret was really a weird idea. It'd look like this: .*(?!,) and .*(?!<,).
That was a long weeds expedition.
And the DSLs?
Ok, so the regexp mechanics is messy and requires a lot of concentration, so why the hell not make it prettier and/or more legible? After all I did say that I value maintainability over compactness most of the time.
Here's a regexp to match the title of a todo.txt file:
let reference = Reference(String.self)
let titlematch = OneOrMore {
ChoiceOf {
One(.whitespace)
OneOrMore(.word)
}
NegativeLookahead {
OneOrMore {
OneOrMore(.word)
One(":")
}
}
}
let regex = Regex {
Anchor.startOfLine
ZeroOrMore {
ChoiceOf {
One("x ")
OneOrMore {
"("
(try? Regex("[A-Z]"))!
") "
}
One(.iso8601Date(timeZone: .gmt))
One(.whitespace)
}
}
NegativeLookahead {
ChoiceOf {
One(.iso8601Date(timeZone: .gmt))
OneOrMore {
One(.whitespace)
OneOrMore(.word)
One(":")
}
}
}
Capture(titlematch, as: reference,
transform: { word -> String in String(word) })
}
let match = input.firstMatch(of: regex)
if let match {
return match[reference].trimmingCharacters(in: CharacterSet.whitespacesAndNewlines) // because we capture the last space
} else {
return nil
}
reference is the variable that should hold the mattern once it's matched. It's weird, but not any weirder than the numbered capture groups, so there.
Because of the Builder's very complex type inference, I had to split the "two" regexps, otherwise, the compiler failed to build. That's a legibility problem because that thing I store in titlematch is really a part of the bigger regexp, and the call site is now murkier. Plus it's a variable, so does it mean I can use it multiple times? In capture groups? Unclear, so probably not.
Then there is .word... it doesn't mean match a word. It means match a character that could be part of a word. Yes. A single character. When you're not paying attention, it can bite you really bad.
I'll set aside the fact that I capture an extra space every now and again. I'm sure that there is a way to avoid doing it, but the regexp was complicated enough as it was and I spent way too much time on it that I care to admit. It's a peculiarity of todo.txt rather than of the regex system, but a space is used to separate the elemets of the format, except when it's in the title.
Also, why is there an actual regular expression in there? Because insofar as I can understand it, you can't express [A-Z] (any capital latin letter) with this system. It's either .word (any character that can be part of a word, uppercase or not), or something else that's not a character.
Also, also, One doesn't accept a closure like OneOrMore does, so I'm forced to accept multiple priorities ( (LETTER) ) instead of only one, for some reason.
Let's dig into that one, shall we? So we're looking for some text that is after the start of the line, after the optional x that marks completion of the task, the (LETTER) marking the priority, and after the optional two dates (creation and optionally completion), but before any special character ( + and @ denote project and context, respectively) or key:value pair.
If you got that by looking at the code instantly, congratulations. I didn't. And I wrote it.
For reference, the regexp would look something like that (I don't include the date formatting, because I'm lazy and would probably do it after I extracted the matches): ^(x |\([A-Z]\) |[0-9-]| )+([\w ]+)(?! \w+:\w+)
OK, sure, this expression is a bit cryptic, and captures an extra space as well for the title. Because I didn't go into details for the date, it also doesn't quite work, because it lets dates with less or more than 3 components pass, instead of only valid ones.
But these 40-ish lines really aren't that clear to me in the things they will and will not match. Especially with the callsite being split into variables, but that's on Swift, not on the DSL thing. To my mind, the regexp is something that you "slide along" your string, stopping when it matches. Yes it's made of blocks and captures and weird characters, but it's kind of the same "thing" as a string, whereas that visual block syntax seems kind of "orthogonal" to the string, not of the same type, and therefore makes it harder for me to think about them.
But it's probably me and my old habit-encrusted brain. Drop me a line if you find an error, or if you disagree with decent arguments!