Writing good tests for your code very often means spending twice as much time coding them than on the things you test themselves.
It is good practice though to verify as much as possible that the code you write is valid, especially if that code is going to be public or included in someone else's work.
In my workflow I insist on the notion of ownership :
The bottomline for me is this: if there are several people on a project, I want clearly defined ownership. It's not that I won't fix a bug in someone else's code, just that they own it and therefore have to have a reliable way of testing that my fix works.
Tests solve part of that problem. My code, my tests. If you fix my code, run my tests, I'm fairly confident that you didn't wreck the whole thing. And that I won't have to spend a couple of hours figuring out what it is that you did.
This a a very very very light constraint when you compare it to methodologies like TDD, but it's a required minimum for me.
Plus, it's not that painful, except...
Testing every case
In my personal opinion, the tests that are hardest to do right are the ones that have a very large input range, with a few failure/continuity points.
If, for instance, and completely randomly, of course, you had an application where the tilt of the phone changes the state of the app (locked/unlocked, depending on whether the phone is lying flat-ish on the table or not:
from -20º to 20º the app is locked
from 160º to 200º the app is locked
the rest of the time it's not locked
All of that modulo 360, of course
So you have a function that takes the current pitch angle, and returns if we should lock or not:
Does it work? Does it work modulo 360? What would a unit test for that function even look like? A for loop?
I have been looking for a way to do that kind of test for a while, which is why I published HoledRange (now Domains 😇) a while back, as part of my hacks.
What I wanted is to write my tests kind of like this (invalid code on so many levels):
for x in [-1000.0...1000.0].randomSelection {
let unitCircleAngle = x%360.0
if unitCircleAngle >= 340 || unitCircle <= 20 {
XCTAssert(pitchLock(x))
} else if unitCircleAngle >= 160 && unitCircle <= 200 {
XCTAssert(pitchLock(x))
} else {
XCTAssertFalse(pitchLock(x))
}
}
This way of testing, while vaguely valid, leaves so many things flaky:
how many elements in the random selection?
how can we make certain values untestable (because we address them somewhere else, for instance)
what a lot of boilerplate if I have multiple functions to test on the same range of values
I can't reuse the same value for multiple tests to check function chains
Function builders
I have been fascinated with @_functionBuilder every since it was announced. While I don't feel enthusiastic about SwiftUI (in french), that way to build elements out of blocks is something I have wanted for years.
Making them is a harrowing experience the first time, but in the end it works!
What I wanted to use as syntax is something like this:
func myPlus(_ a: Int, _ b: Int) -> Int
DomainTests<Int> {
Domain(-10000...10000)
1000000
Test { (a: Int) in
XCTAssert(myPlus(a, 1) == a+1, "Problem with value\(a)")
XCTAssert(myPlus(1, a) == a+1, "Problem with value\(a)")
}
Test { (a: Int) in
let random = Int.random(in: -10000...10000)
XCTAssert(myPlus(a, random) == a+random, "Problem with value\(a)")
XCTAssert(myPlus(random, a) == a+random, "Problem with value\(a)")
}
}.random()
This particular DomainTests runs 1000000 times over $$D=[-10000;10000]$$ in a random fashion.
Note the Test builder that takes a function with a parameter that will be in the domain, and the definition that allows to define both the test domain (mandatory) and the number of random iterations (optional).
If you want to test every single value in a domain, the bounding needs to be Strideable, ie usable in a for-loop.
DomainTests<Int> {
Domain(-10000...10000)
Test { (a: Int) in
XCTAssert(myPlus(a, 1) == a+1, "Problem with value\(a)")
XCTAssert(myPlus(1, a) == a+1, "Problem with value\(a)")
}
Test { (a: Int) in
let random = Int.random(in: -10000...10000)
XCTAssert(myPlus(a, random) == a+random, "Problem with value\(a)")
XCTAssert(myPlus(random, a) == a+random, "Problem with value\(a)")
}
}.full()
Conclusion
A couple of hard working days plus a healthy dose of using that framework personally means this should be ready-ish for production.
If you are a maths-oriented dev and shiver at the idea of untested domains, this is for you 😬
This is the last part of a 3-parts series. In part 1, I tried to make sense of how it works and what we are trying to achieve, and in part 2, we set up the training loop.
Model Predictions
We have a trained model. Now what?
Remember, a model is a series of giant matrices that take an input like you trained it on, and spits out the list of probabilities associated with the outputs you trained it on. So all you have to do is feed it a new input and see what it tells you:
let input = [1.0, 179.0, 115.0]
let unlabeled : Tensor<Float> = Tensor<Float>(shape: [1, 3], scalars: input)
let predictions = model(unlabeled)
let logits = predictions[0]
let classIdx = logits.argmax().scalar! // we take only the best guess
print(classIdx)
17
Cool.
Cool, cool.
What?
Models deal with numbers. I am the one who assigned numbers to words to train the model on, so I need a translation layer. That's why I kept my contents structure around: I need it for its vocabulary map.
The real code:
let w1 = "on"
let w2 = "flocks"
let w3 = "settlement"
var indices = [w1, w2, w3].map {
Float(contents.indexHelper[$0.hash] ?? 0)
}
var wordsToPredict = 50
var sentence = "\(w1) \(w2) \(w3)"
while wordsToPredict >= 0 {
let unlabeled : Tensor<Float> = Tensor<Float>(shape: [1, 3], scalars: indices)
let predictions = model(unlabeled)
for i in 0..<predictions.shape[0] {
let logits = predictions[i]
let classIdx = logits.argmax().scalar!
let word = contents.vocabulary[Int(classIdx)]
sentence += " \(word)"
indices.append(Float(classIdx))
indices.remove(at: 0)
wordsToPredict -= 1
}
}
print(sentence)
on flocks settlement or their enter the earth; their only hope in their arrows, which for want of it, with a thorn. and distinction of their nature, that in the same yoke are also chosen their chiefs or rulers, such as administer justice in their villages and by superstitious awe in times of old.
Notice how I remove the first input and add the one the model predicted at the end to keep the loop running.
Seeing that, it kind of makes you think about the suggestions game when you send text messages eh? 😁
Model Serialization
Training a model takes a long time. You don't want a multi-hour launch time on your program every time you want a prediction, and maybe you even want to keep updating the model every now and then. So we need a way to store it and load it.
Thankfully, tensors are just matrices, so it's easy to store an array of arrays of floats, we've been doing that forever. They are even Codable out of the box.
In my particular case, the model itself needs to remember a few things to be recreated:
the number of inputs and hidden nodes, in order to recreate the Reshape and LSTMCell layers
the internal probability matrices of both RNNs
the weigths and biases correction matrices
Because they are codable, any regular swift encoder will work, but I know some of you will want to see the actual matrices, so I use JSON. It is not the most time or space efficient, it does not come with a way to validate it, and JSON is an all-around awful storage format, but it makes a few things easy.
My resulting JSON file is around 70MB (25 when bzipped), so not too bad.
When you serialize your model, remember to serialize the vocabulary mappings as well! Otherwise, you will lose the word <-> int translation layer.
That's all , folks!
This was a quick and dirty intro to TensorFlow for some, Swift for others, and SwiftTensorflow for most.
It definitely is a highly specialized and quite brittle piece of software, but it's a good conversation piece next time you hear that ML is going to take over the world.
Feel free to drop me comments or questions or corrections on Twitter!
This is the second part of a series. If you haven't, you should read part 1...
Model Preparation
The text I trained the model on is available on the Gutenberg Project. Why this one? Why not?
It has a fairly varied vocabulary and a consistency of grammar and phrase structures that should trigger the model. One of the main problems of picking the wrong corpus is that it leads to cycles in the prediction with the most common words, e.g. "and the most and the most and the most and the" because it's the pattern that you see most in the text. Tacitus, at least, should not have such repetitive turns of phrase. And it's interesting in and of itself, even though it's a bit racist, or more accurately, elitist. 😂
One of the difficult decisions is choosing the type of network we will be trying to train. I tend to have fairly decent results with RNNs on that category of problems so that's what I'll use. The types and sizes of these matrices is wayyyyy beyond the scope of this piece, but RNNs tend to be decent generalists. Two RNN/LSTM layers of 512 hidden nodes will give me enough flexibility for the task and good accuracy.
What are those and how do they work? You can do a deep dive on LSTM and RNN on Wikipedia, but the short version is, they work well with sequences because the order of the input is in and of itself one of the features it deals with. Recommended for handwriting recognition, speech recognition, or pattern analysis.
Why two layers? The way you "nudge" parameters in the training phase means that you should have as many layers as you think there are orders of things in your dataset. In the case of text pattern recognition, you can say that what matters is the first order of recognition (say, purely statistical "if this word then this word") or you can add a second order where you try to identify words that tend to have similar roles in the structure (e.g. subject verb object) and take that into account as well. Higher orders than that, in this particular instance, have very little meaning unless you are dealing with, say, a multilingual analysis.
That's totally malarkey when you look at the actual equations, but it helps to see it that way. Remember that you deal with probabilities, and that the reasoning the machine will learn is completely alien to us. By incorporating orders in the model, you make a suggestion to the algorithm, but you can't guarantee that it will take that route. It makes me feel better, so I use it.
Speaking of layers, it is another one of these metaphors that help us get a handle of things, by organizing our code and the way the algorithm treats the data.
You have an input, it will go through a first layer of probabilities, then a second layer will take the output of the first one, and apply its probabilities, and then you have an output.
Let's look at the actual contents of these things:
Input is a list of trigrams associated with a word ( (borrowing a warrant) -> from, (his father Laertes) -> added, etc
The first layer has a single input (the trigram), and a function with 512 tweakable parameters to output the label
The second layer is trickier: it takes the 512 parameters of the first layer, and has 512 tweakable parameters of its own, to deal with the "higher order" of the data
It sounds weird, but it works, trust me for now, you'll experiment later.
The very first step is "reshaping" the trigrams so that LSTM can deal with it. We basically turn the matrices around and chunk them so that they are fed to the model as single inputs, 3 of them, in this order. It is actually a layer of its own called Reshape.
And finally, we need to write that using this model requires these steps:
reshape
rnn1
rnn2
get something usable out of it
The code, then the comments:
struct TextModel : Layer {
@noDerivative var inputs : Int
@noDerivative var hidden : Int
var reshape : Reshape<Float>
var rnn1 : RNN<LSTMCell<Float>>
var rnn2 : RNN<LSTMCell<Float>>
var weightsOut : Tensor<Float> {
didSet { correction = weightsOut+biasesOut }
}
var biasesOut : Tensor<Float> {
didSet { correction = weightsOut+biasesOut }
}
fileprivate var correction: Tensor<Float>
init(input: Int, hidden: Int, output: Int, weights: Tensor<Float>, biases: Tensor<Float>) {
inputs = input
self.hidden = hidden
reshape = Reshape<Float>([-1, input])
let lstm1 = LSTMCell<Float>(inputSize: 1, hiddenSize: hidden)
let lstm2 = LSTMCell<Float>(inputSize: hidden, hiddenSize: hidden)
rnn1 = RNN(lstm1)
rnn2 = RNN(lstm2)
weightsOut = weights
biasesOut = biases
correction = weights+biases
}
@differentiable
func runThrough(_ input: Tensor<Float>) -> Tensor<Float> {
let reshaped = reshape.callAsFunction(input).split(count: inputs, alongAxis: 1)
let step1 = rnn1.callAsFunction(reshaped).differentiableMap({ $0.cell })
let step2 = rnn2.callAsFunction(step1).differentiableMap({ $0.cell })
let last = withoutDerivative(at:step2[0])
let red = step2.differentiableReduce(last, { (p,e) -> Tensor<Float> in return e })
return red
}
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
let step2out = runThrough(input)
let step3 = matmul(step2out, correction)
return step3
}
}
The RNN/LTSM have been talked about, but what are these two functions?
callAsFunction is the only one needed. I have just decided to split the algorithm in two: the part where I "just" pass through layers, and the part where I format the output. Everything in runThrough could be written at the top of callAsFunction.
We follow the steps outlined previously, it all seems logical, even if the details aren't quite clear yet.
What is it with the @noDerivative and @differentiable annotations?
Because we are dealing with a structure (model, layer, etc...) that not only should but will be adjusted over time, it is a way to tell the system which parts are important to that adjustment:
all properties except those maked as not derivative will be nudged potentially, so it makes sense to mark the number of inputs as immutable, and the rest as "nudgeable"
all the functions that calculate something that will be used in the "nudging" need to have specific maths properties that make the change non-random. We need to know where we are and where we were going. We need a position, and a speed, we need a value and its derivative
Ugh, maths.
Yeah.
I am obviously oversimplifying everything to avoid scaring away everyone from the get go, but the idea should make sense if you look at it this way:
Let's take a blind man trying to shoot an arrow at a target
You ask them to shoot and then you'll correct them based on where the arrow lands
It hits the far left of the target
You tell them to nudge the aim to the right
The problem is that "more right" isn't enough information... You need to tell them to the right a little (new position and some information useful for later, you'll see)
The arrow lands slightly to the right of the center
You tell the archer to aim to the left but less than their movement they just made to the right.
Two pieces of information: one relative to a direction, and one relative to the rate of change. The other name of the rate of change is the derivative.
Standard derivatives are speed to position (we are here, now we are there, and finally we are there, and the rate of change slowed, so the next position won't be as far from this one as the one was to the previous one), or acceleration to speed (when moving, if your speed goes up and up and up, you have a positive rate of change, you accelerate).
That's why passing through a layer should preserve the two: the actual values, and the speed at which we are changing them. Hence the @differentiable annotation.
(NB for all you specialists in the field reading that piece... yes I know. I'm trying to make things more palatable)
"But wait", say the most eagle-eyed among you, "I can see a withoutDerivative in that code!"
Yes. RNN is peculiar in the way that it doesn't try to coerce the dimensions of the results. It spits out all the possible variants it has calculated. But in practice, we need only the last one. Taking one possible outcome out of many cancels out the @differentiable nature of the function, because we actually lose some information.
This is why we only partially count on the RNN's hidden parameters to give us a "good enough" result, and need to incorporate extra weights and biases that are derivable.
The two parts of the correction matrix, will retain the nudge speed, as well as reshape the output matrix to match the labels: matrix addition and multiplications are a bit beyond the scope here as well (and quite frankly a bit boring), but that last step ( step3 in the code ) basically transform a 512x512x<number of labels> matrix, into a 2x<numbers of labels> : one column to give us the final probabilities, one for each possible label.
If you've made it this far, congratulations, you've been through the hardest.
Model Training
OK, we have the model we want to use to represent the various orders in the data, how do we train it?
To continue with the blind archer metaphor, we need the piece of code that acts as the "corrector". In ML, it's called the optimizer. We need to give it what the archer is trying to do, and a way to measure how far off the mark the archer is, and a sense of how stern it should be (do we do a lot of small corrections, or fewer large ones?)
The measure of the distance is called the "cost" function, or the "accuracy" function. Depending on how we look at it we want to make the cost (or error) as low as possible, and the accuracy as high as possible. They are obviously linked, but can be expressed in different units ("you are 3 centimeters off" and "you are closer by 1%"). Generally, loss has little to no meaning outside of the context of the layers ( is 6 far? close? because words aren't sorted in any meaningful way, we are 6.2 words away from the ideal word doesn't mean much), while accuracy is more like a satisfaction percentage (we are 93% satisfied with the result, whatever that means).
let predictions = model(aBunchOfFeatures)
let loss = softmaxCrossEntropy(logits: predictions, labels: aBunchOfLabels)
print("Loss test: \(loss)")
Loss test: 6.8377414
In more human terms, the best prediction we have is 10% satisfying, because the result is 6.8 words away from the right one. 😬
Now that we know how to measure how far off the mark we are (in two different ways), we need to make a decision about 3 things:
Which kind of optimizer we want to use (we'll use Adam, it's a good algorithm for our problem, but other ones exist. For our archer metaphor, it's a gentle but firm voice on the corrections, rather than a barking one that might progress rapidly at first then annoy the hell out of the archer)
What learning rate we want to use (do we correct a lot of times in tiny increments, or in bigger increments that take overall less time, but might overcorrect)
How many tries we give the system to get as close as possible
You can obviously see why the two last parameters are hugely important, and very hard to figure out. For some problems, it might be better to use big steps in case we find ourselves stuck, for others it might be better to always get closer to the target but by smaller and smaller increments. It's an art, honestly.
Here, I've used a learning rate of 0.001 (tiny) and a number of tries of 500 (medium), because if there is no way to figure out the structure of the text, I want to know it fast (fewer steps), but I do NOT want to overshoot(small learning rate).
Let's setup the model, the correction matrices, and the training loop:
var weigths = Tensor<Float>(randomNormal: [512, contents.vocabulary.count]) // random probabilities
var biases = Tensor<Float>(randomNormal: [contents.vocabulary.count]) // random bias
var model = TextModel(input:3, hidden: 512, output: contents.vocabulary.count, weights: weigths, biases: biases)
Now let's setup the training loop and run it:
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
var randomSampleSize = contents.original.count/15
var randomSampleCount = contents.original.count / randomSampleSize
print("Doing \(randomSampleCount) samples per epoch")
for epoch in 1...epochCount {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for training in contents.randomSample(splits: randomSampleCount) {
let (sampleFeatures,sampleLabels) = training
let (loss, grad) = model.valueWithGradient { (model: TextModel) -> Tensor<Float> in
let logits = model(sampleFeatures)
return softmaxCrossEntropy(logits: logits, labels: sampleLabels)
}
optimizer.update(&model, along: grad)
let logits = model(sampleFeatures)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: sampleLabels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epoch % 10 == 0 {
print("avg time per epoch: \(t.averageDeltaHumanReadable)")
print("Epoch \(epoch): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
A little bit of explanation:
We will try 500 times ( epochCount )
At each epoch, I want to test and nudge for 15 different combinations of trigrams. Why? because it avoids the trap of optimizing for some specific turns of phrase
We apply the model to the sample, calculate the loss, and the derivative, and update the model with where we calculate we should go next
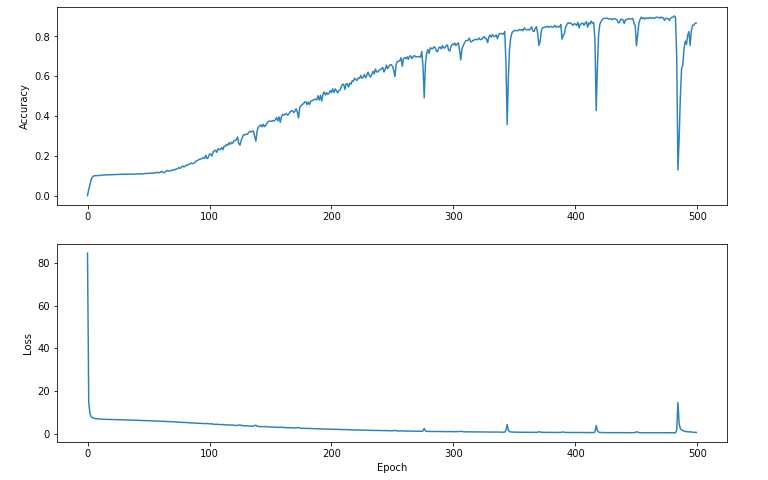
We like to keep these values in an array to graph them. What does it look like?
We can see that despite the dips and spikes, because we change the samples often and don't try any radical movement, we tend to better and better results. We don't get stuck in a ditch.
Next part, we'll see how to use the model. Here's a little spoiler: I asked it to generate some random text:
on flocks settlement or their enter the earth; their only hope in their arrows, which for want of it, with a thorn. and distinction of their nature, that in the same yoke are also chosen their chiefs or rulers, such as administer justice in their villages and by superstitious awe in times of old.
It's definitely gibberish when you look closely, but from a distance it looks kind of okayish for a program that learned to speak entirely from scratch, based on a 10k words essay written by fricking Tacitus.
To get your degree in <insert commerce / political school name here>, there is a last exam in which you need to talk with a jury of teachers. The rule is simple, if the student is stumped or hesitates, the student has failed. If the student manages to last the whole time, or manages to stump the jury or makes it hesitate, the student passes. This particular student was having a conversation about geography, and a juror thought to stump the candidate by asking "what is the depth of <insert major river here>?" to which the student, not missing a beat answered "under which bridge?", stumping the juror.
Old student joke/legend
Programming is part of the larger tree of knowledge we call computer science. Everything we do has its roots in maths and electronics. Can you get by with shoddy reasoning and approximate "that should work" logic? Sure. But in the same way you can "get by" playing the piano using only the index finger of your hands. Being able to play chopsticks makes you as much of a pianist as being able to copy/paste stackoverflow answers makes you a programmer/developer.
The problem is that in my field, the end-user (or client, or "juror", or "decision maker") is incapable of distinguishing between chopsticks and Brahms, not because of a lack of interest, but because we, as a field, have become experts at stumping them. As a result, we have various policies along the lines of "everyone should learn to code" being implemented worldwide, and I cynically think it's mostly because the goal is to stop getting milked by so-called experts that can charge you thousands of monies for the chopsticks equivalent of a website.
To me, the problem doesn't really lie with the coding part. Any science, any technical field, requires a long formation to become good at. Language proficiency, musical instruments, sports, dancing, driving, sailing, carpentry, mechanical engineering, etc... It's all rather well accepted that these fields require dedication and training. But somehow, programming should be "easy", or "intuitive".
That's not to say I think it should be reserved to an elite. These other fields aren't. I have friends who got extremely good at guitars by themselves, and sports are a well known way out of the social bog. But developers seem to be making something out of nothing. They "just" sit down and press keys on a board and presto, something appears and they get paid. It somehow seems unfair, right?
There are two aspects to this situation: the lack of nuanced understanding on the person who buys the program, and the overly complicated/flaky way we programmers handle all this. I've already painted with a very broad brush what we developers feel about this whole "being an industry" thing.
So what's the issue on the other side? If you ask most customers (and students), they respond "obfuscation" or a variant of it. In short, we use jargon, technobabble, which they understand nothing of, and are feeling taken advantage of when we ask for money. This covers the whole gamut from "oh cool, they seem to know what they are talking about, so I will give them all my money" to "I've been burned by smart sounding people before, I don't trust them anymore", to "I bet I can do it myself in under two weeks", to "the niece of the mother of my friend is learning to code and she's like 12, so I'll ask her instead".
So, besides reading all of Plato's work on dialectic and how to get at the truth through questions, how does one differentiate between a $500 website and a $20000 one? Especially if they look the same?
Well, in my opinion as a teacher, for which I'm paid to sprinkle knowledge about computer programming onto people, there are two important things to understand about making software to evaluate the quality of a product:
Programming is exclusively about logic. The difficulty (and the price) scales in regards to the logic needed to solve whatever problem we are hired to solve
We very often reuse logic from other places and combine those lines of code with ours to refine the solution
Warning triggers that make me think the person is trying to sell me magic pixie dust include:
The usual bullshit-bingo: if they try to include as many buzzwords (AI, machine learning, cloud, big data, blockchain,...) as possible in their presentation, you have to ask very pointed question about your problem, and how these things will help you solve it
If they tell you they have the perfect solution for you even though they asked no question, they are probably trying to recycle something they have which may or may not work for your issues
A word of warning though: prices in absolute aren't a factor at all. In the same way that you'd probably pay quite naturally a whole lot more money for a bespoke dinner table that is exactly what you envision in your dreams than the one you can get in any furniture store, your solution cannot be cheaper than off-the-shelf. Expertise and tailoring cannot be free. Balking at the price when you have someone who genuinely is an expert in front of you, and after they announced their price is somewhat insulting. How often do you go to the bakery and ask the question "OK, so your cake is really good, and all my friends recommend it, and I know it's made with care, but, like, $30 is way too expensive... how about $15?"
I have also left aside the question of visual design. it's not my field, I suck at it, and I think that it is an expert field too, albeit more on the "do I like it?" side of the equation than the "does it work?" one, when it comes to estimating its value. It's like when you buy a house: there are the foundations, and the walls, and the roof, and their job is to answer the question "will I still be protected from the outside weather in 10 years?", whereas the layout, the colors of the walls, and the furniture are the answer to the question "will I still feel good in this place in 10 years?". Thing is, with software development as well, you can change the visuals to a certain extent (up to the point when you need to change the position of the walls, to continue with the metaphor), but it's hard to change the foundations.